Original Link: https://www.anandtech.com/show/9582/intel-skylake-mobile-desktop-launch-architecture-analysis
The Intel Skylake Mobile and Desktop Launch, with Architecture Analysis
by Ian Cutress on September 1, 2015 11:05 PM EST
Intel’s 6th Generation of its Core product line, Skylake, is officially launching today. We previously saw the performance of the two high end Skylake-K 91W processors, but that was limited in detail as well as product. So it is today that Intel lifts the lid on the other parts from 4.5 W in mobile through Core M, to 15W/28W in Skylake-K, 45W in Skylake-H and then the 35W/65W mêlée of socketed Skylake-S parts. For today's formal launch we will be taking a look at the underlying Skylake architecture, which was unveiled by Intel at their recent Intel Developer Forum this August.
The (Abridged) March to Skylake and Beyond
For Intel, the Skylake platform is their second swing at processors built on the 14nm process node, following the launch of Broadwell late in 2014. The main difference from Broadwell is that Skylake is marked as a substantial change in the underlying silicon, introducing new features and design paradigms to adjust to the requirements that now face computing platforms in 2015-2016, even though the design of Skylake started back in 2012.
| Intel's Tick-Tock Cadence | |||||
| Microarchitecture | Process Node | Tick or Tock | Release Year | ||
| Conroe/Merom | 65nm | Tock | 2006 | ||
| Penryn | 45nm | Tick | 2007 | ||
| Nehalem | 45nm | Tock | 2008 | ||
| Westmere | 32nm | Tick | 2010 | ||
| Sandy Bridge | 32nm | Tock | 2011 | ||
| Ivy Bridge | 22nm | Tick | 2012 | ||
| Haswell | 22nm | Tock | 2013 | ||
| Broadwell | 14nm | Tick | 2014 | ||
| Skylake | 14nm | Tock | 2015 | ||
| Kaby Lake (link)? | 14nm | Tock | 2016 ? | ||
Intel’s strategy since 2008 is one of tick-tock, alternating between reductions in process node at the point of manufacture (which reduces die area, leakage and power consumption but keeps the layout similar) and upgrades in processor architecture (improve performance, efficiency) as shown above. Skylake is the latter, which will be explained in the next few pages.
The Launch Today
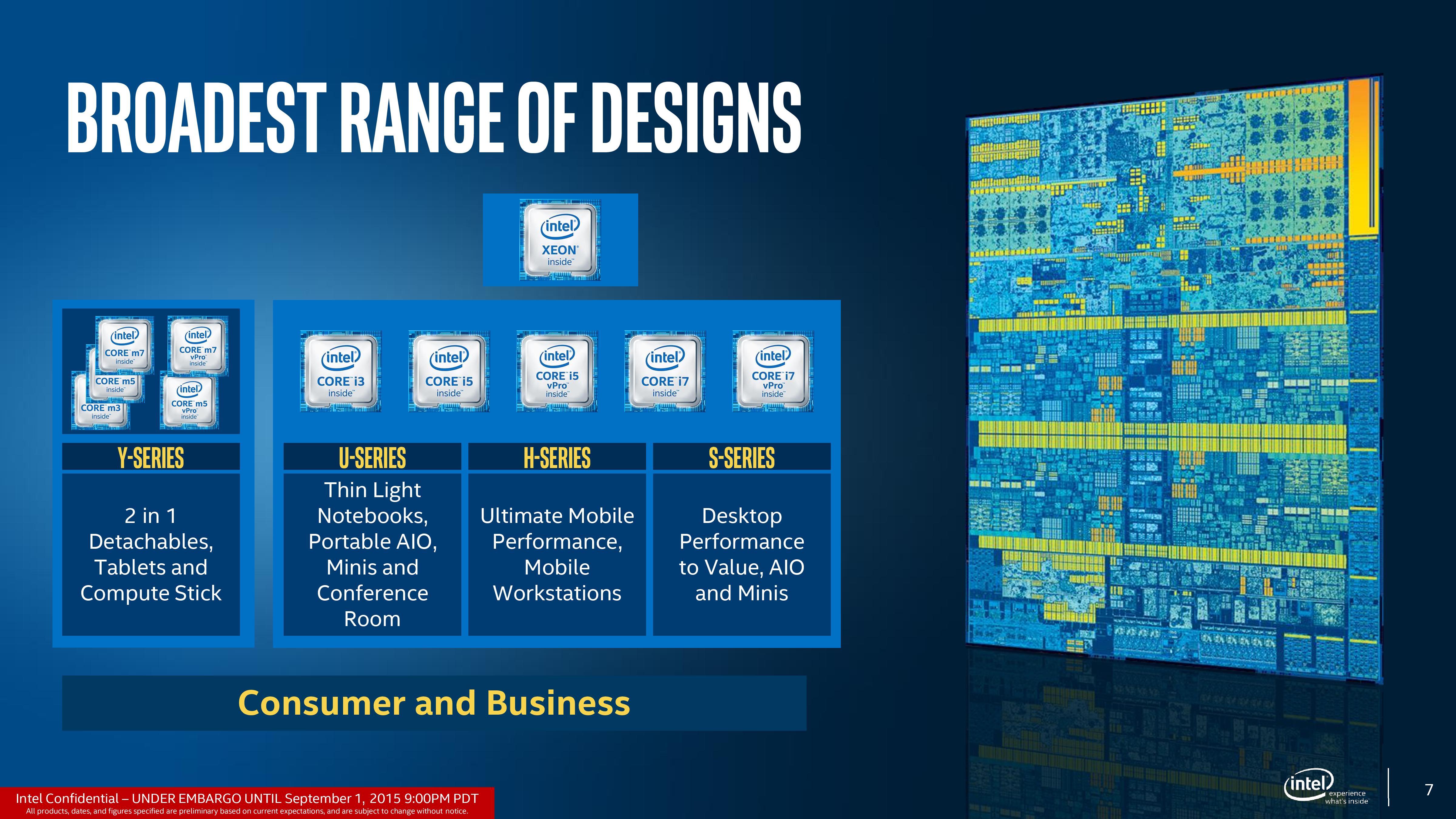
Typically a complete product stack of processors for Intel runs the gamut from low power to high power, including i7, i5, i3, Pentium, Celeron and Xeon. This also applies on the integrated graphics side, from base HD designs to GT1, GT2, GT3/e and beyond. In a departure from their more recent launches, Intel is launching nearly their entire Skylake product stack today in one go, although there are some notable exceptions.

All of the Core M processors are launching today, as are the i3/i5/i7 models and two new Xeon mobile processors. From a power perspective this means Intel is releasing everything from the 4.5W ultra-mobile Core M through the large 65W desktop models, along with the previously released 91W desktop SKUs. What parts that are not launching today are the Pentium/Celeron processors, the E3 v5 desktop Xeons, and the vPro enabled processors. Put another way, Intel is launching most of their 2+2 and 4+2 SKUs today, with the exception of budget SKUs and some of Intel's specialized IT/workstation SKUs.
Meanwhile for SKUs with Intel's high end Iris and Iris Pro integrated graphics – the 2+3 and 4+4 die configurations – Intel will also be launching these at a later time. For the Iris configurations Intel is staying relatively vague for the moment, telling the press that we should expect to see those parts launch in Q4'15/Q1'16. That being said, the annual Consumer Electronics Expo in Las Vegas is being held in the first week of January, so we imagine we should see some movement there, if not before.
Today's launch will also come with a small change in how Intel brands their Core M lineup of processors. With the Broadwell generation Intel used a mix of 4 and 5 character product identifiers, e.g. Core M 5Y10a. However for the Skylake generation the Core M naming scheme is being altered to better align with Intel's existing mainstream Core i-series parts and hopefully cut down on some of the confusion in the process. Thus we now have Core m3, m5 and m7 to complement the i3, i5 and i7 already used on Intel's more powerful processors. This will be represented by both Intel and the OEMs when it comes down to device design to afford greater differentiation in the Core M product line.

Launching secondary to the processors, and perhaps not promoted as much, are the new Intel 100-series chipsets. Specifically, there will be desktop motherboard manufacturers announcing motherboards based on H170, B150, H110 and Q170 today, although which of these will be available when (for both desktop and other use) is not known. We have been told that the business oriented chipsets (B150/Q1x0) will have information available today but won’t necessarily ‘launch’. We have information on these later in the review
As a result of all these processor and chipset families coming to market at once, as well as linking up the launch to the Internationale Funkausstellung Berlin (IFA) show held in Berlin, Germany, Intel’s launch is going to be joined by a number of OEMs releasing devices as well. Over the course of IFA this week (we have Andrei on site), we expect Lenovo, ASUS, Dell, HP and others to either announce or release their devices based around Skylake. We covered a number of devices back at Computex in June advertised as having ‘6th Generation’ processors, such as MSI’s AIOs and notebooks, so these might also start to see the light of day with regards to specifications, pricing, and everything else.

A Skylake wafer shown at IDF 2015
The Parts
To cut to the chase, the processor base designs come from five dies in four different packages. The terms ‘Skylake-Y’, ‘Skylake-U’, ‘Skylake-H’ and ‘Skylake-S’ are used as easy referrals and loosely define the power consumption and end product that these go in, but at the end of the day the YUHS designation can specifically segregate the size of the package (the PCB on which the die and other silicon sits). The YUHS processors all feature the same underlying cores, the same underlying graphics units, but differ in orientation and frequency. The best way to refer to these arrangements is by the die orientation, such as 2+2 or 4+4e. This designation means the number of cores (2 or 4) and the level of graphics (2 or 3e or 4e).

Core M designs, which fall under Skylake’s Y-series, will be available in a 2+2 configuration only which is similar to the Broadwell offerings. This allows Intel to keep around the 4.5W margins, and as with Broadwell, many of these processors will have a low base frequency and a high turbo mode to take advantage of burst performance. However, if you read our piece on the problems of OEM design on Broadwell’s Core M, it can depend highly on the device manufacturer as to the end performance you might receive. Intel states that for Skylake, this becomes less of an issue, and we cover this later in this article. By virtue of the desire to reduce the number of packages in these devices, the chipset/IO is integrated on the package. Also to note, DRAM support for Skylake-Y will be limited to LPDDR3/DDR3L, and will not include DDR4 support like the others. We suspect this is either for power reasons or because DDR4 needs more pins, but when DDR4L comes to play we should see future Core M platforms migrate in that direction.
Skylake-U also follows a similar path to previous Intel generations, being available in 15W and 28W versions. What is new comes down to the configurations – 2+2 as expected but also 2+3e models will be available later in the year. The extra ‘e’ means that these versions will also include Intel’s eDRAM solution which we have seen to be significantly useful when it comes to graphics performance. In previous eDRAM designs, this was only in available in 128MB variants, but for Skylake-U we will start to see 64MB versions. These will also be on package, similar to the chipset/IO, resulting in a 42x24mm package arrangement.
The H processor family, such as Skylake-H, is typically found in high end notebooks or specific market devices such as all-in-ones where the ability to deal with the extra TDP (45W) is easier. Historically the H processor family is BGA only, meaning it can only be found in products soldered directly to the motherboard. With Broadwell-H, Intel released a handful of socketable processors for desktop/upgradeable AIO designs, but with the information given above this might not happen for Skylake. Nevertheless, Skylake-H will feature 45W parts with 4+2 and 4+4e configurations, the latter having 128MB of eDRAM. Also similarly to previous H designs, the chipset is external to the processor package.
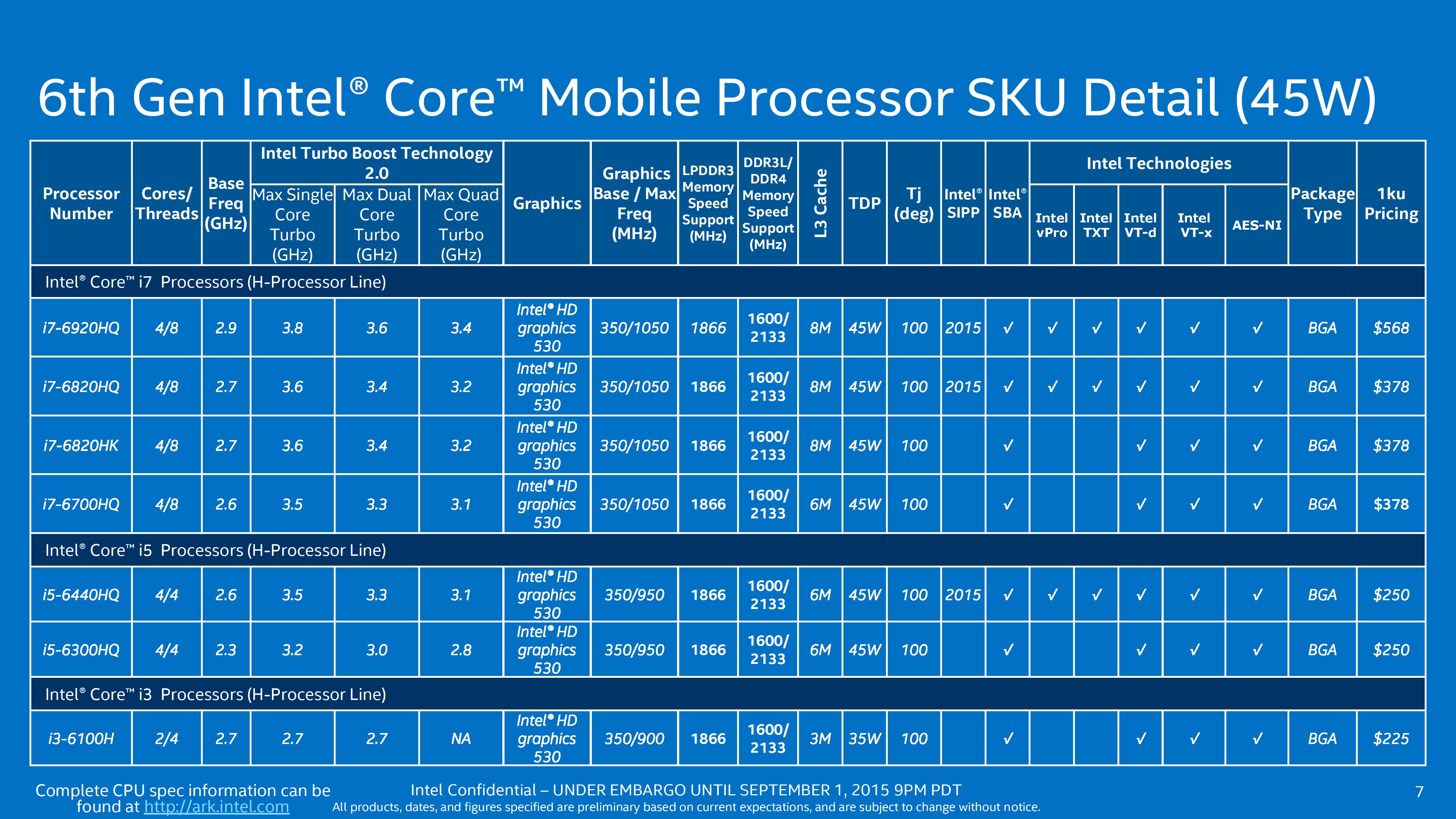
Skylake-S represents everything desktop, including the K processors. Some users will be disappointed that despite the move to 14nm, Intel is still retaining the 2+2 and 4+2 configurations with no six-core configuration on the horizon without moving up to the high-end desktop (HEDT) platform (and back two generations in core architecture). Nevertheless, alongside the two 91W overclocking ‘Skylake-K’ parts we have seen already, Intel will launch the regular 65W parts (e.g. i7-6700, i5-6600, i3-6100) and lower power ‘Skylake-T’ 45W (i7-6700T, i5-6600T, i3-6100T) parts as well. These will all have GT2 graphics, varying in frequency, as well as varying in cache sizes and some feature sets. We go more into detail over the next few pages.






We will go over each of the product markets in turn through this review, but the gallery above showcases the 48 different processors that Intel is prepared to announce at this point. This includes Pentium information as well as a few GT3e products (HD Graphics 550, 48 EUs with 64MB eDRAM) that will be released over the next two quarters.
A Small Note on Die Size and Transistor Counts
In a change to Intel’s previous strategy on core design disclosure, we will no longer be receiving information relating to die size and transistor counts as they are no longer considered (by Intel) to be relevant to the end-user experience. This data in the past might have also given Intel's compeititors more information in the public domain than ultimately they would have wanted. But as you might imagine, at AnandTech we want this information – die size allows us to indicate metrics towards dies per wafer and the capable throughput of a fab producing Intel processors. Transistor count is a little more esoteric, but it can indicate where effort, die area and resources are being geared. In the past we have noted how proportionally more die area and transistors are being partitioned in favor of graphics, and changes in that perspective can indicate the market directions that Intel deems as important.
Obtaining die size area is easier than transistor count, as all that needs to be done is to pop off a heatspreader and bring out the calipers (then assume that there’s no frivolous extra silicon, which seems counterintuitive as die area is proportional to dies per wafer and thus potential revenue). With transistor count, it was not clear if Intel would be providing at a minimum a set of false-color die shots with regions marked, meaning that if this is not the case then when other analysts are able to do an extensive SEM analysis, we will get some information at least.

But for now, this is what we know:
| CPU Specification Comparison | |||||
| CPU | Process Node |
Cores | GPU | Transistor Count (Schematic) |
Die Size |
| Intel Skylake-K 4+2 | 14nm | 4 | GT2 | ? | 122.4 mm2 |
| Intel Skylake-Y 2+2 | 14nm | 2 | GT2 | ? | 98.5mm2 |
| Intel Broadwell-H 4+3e | 14nm | 4 | GT3e | ? | ? |
| Intel Haswell-E 8C | 22nm | 8 | - | 2.6 B | 356 mm2 |
| Intel Haswell-S 4+2 | 22nm | 4 | GT2 | 1.4 B | 177 mm2 |
| Intel Haswell ULT 2+3 | 22nm | 2 | GT3 | 1.3 B | 181 mm2 |
| Intel Ivy Bridge-E 6C | 22nm | 6 | - | 1.86 B | 257 mm2 |
| Intel Ivy Bridge 4+2 | 22nm | 4 | GT2 | 1.2 B | 160 mm2 |
| Intel Sandy Bridge-E 6C | 32nm | 6 | - | 2.27 B | 435 mm2 |
| Intel Sandy Bridge 4+2 | 32nm | 4 | GT2 | 995 M | 216 mm2 |
| Intel Lynnfield 4C | 45nm | 4 | - | 774 M | 296 mm2 |
| AMD Trinity 4C | 32nm | 4 | 7660D | 1.303 B | 246 mm2 |
| AMD Vishera 8C | 32nm | 8 | - | 1.2 B | 315 mm2 |
This is taken from our Skylake-K package analysis of the 4+2 arrangement.
The Claims
As with any launch, there are numbers abound from Intel to explain how the performance and experience of Skylake is better than previous designs as well as the competition.

As with Haswell and Broadwell, Intel is implementing a mobile first design with Skylake. As with any processor development structure the primal idea is to focus on one power point as being the most efficient and extend that efficiency window as far in either direction as possible. During IDF, Intel stated that having an efficiency window from 4.5W to 91W is a significant challenge, to which we agree, as well as improving both performance and power consumption over Broadwell at each stage.

Starting at 4.5W, we spoke extensively with parts of Intel at IDF due to our Broadwell-Y coverage. From their perspective Broadwell-Y designs were almost too wide ranging, especially for what is Intel’s premium low-power high performance product, and for the vendors placing it in an ill-defined chassis far away from Intel’s recommended designs gave concern to the final performance and user experience. As a result, Intel’s guidelines to OEMs this generation are tightened so that the designers looking for the cheaper Core M plastic implementations can tune their design to get the best out of it. Intel has been working with a few of these (both entry Core M and premium models) to enact the user experience model.
Overall however, Intel is claiming 40% better graphics performance for Core M with the new Generation 9 (Gen9) implementation, along with battery saving and compatibility with new features such as RealSense. Because Core-M will find its way into products from tablets to 2-in-1s and clamshells, we’ve been told that the Skylake design should hit a home-run against the best-selling tablets in the market, along with an appropriate Windows 10 experience. When we get units in to review, we will see what the score is from our perspective on that one.

For the Skylake-Y to Skylake-U transition (and in part, Skylake-H), Intel is claiming a 60% gain in efficiency over Haswell-U. This means either 60% less active power during media consumption or 60% more CPU performance at the same power (measured by synthetics, specifically SPECint_base_rate2006). The power consumption metrics comes from updates relating to the Gen9 graphics, such as multi-plane overlay and fixed-function decoders, as well as additional power/frequency gating between the unslice and slices. We will cover this later in the review. The GPU itself, due to the new functionality, is claiming 40% better graphics performance for Core M during 3DMark synthetic tests.
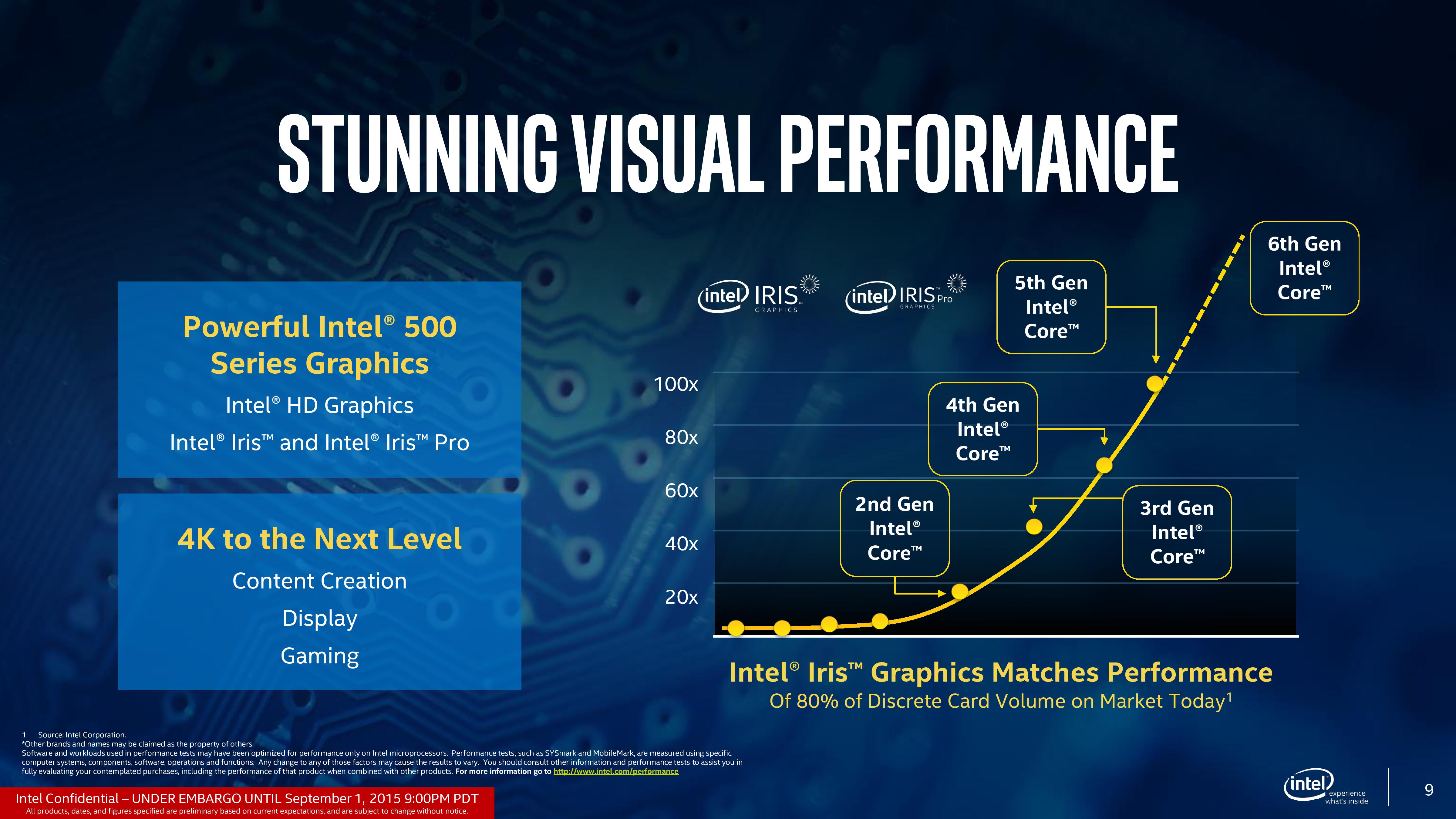
While not being launched today, Intel’s march on integrated graphics is also going to continue. With the previous eDRAM parts, Intel took the crown for absolute IGP performance from AMD, albeit being in a completely different price band. With Skylake, the introduction of a 4+4e model means that Intel’s modular graphics design will now extend from GT1 to GT4, where GT4e has 72 execution units with 128MB of eDRAM in tow. This leads to the claim that GT4e is set to match/beat a significant proportion of the graphics market today.

Back in our Skylake-K review, we were perhaps unimpressed with the generational gain in clock-for-clock performance, although improved multi-threading and frequency ranges helped push the out-of-the-box experience. The other side of that performance is the power draw, and because Skylake is another mobile-first processor, the power aspect becomes important down in mobile devices. We will go through some of these developments to improve power consumption in this article.
A small portion of this page was posted as part of our initial Skylake-K coverage.
The High Level Core
Taking a high level view, the application of the Skylake-S/H architecture features results in the following:
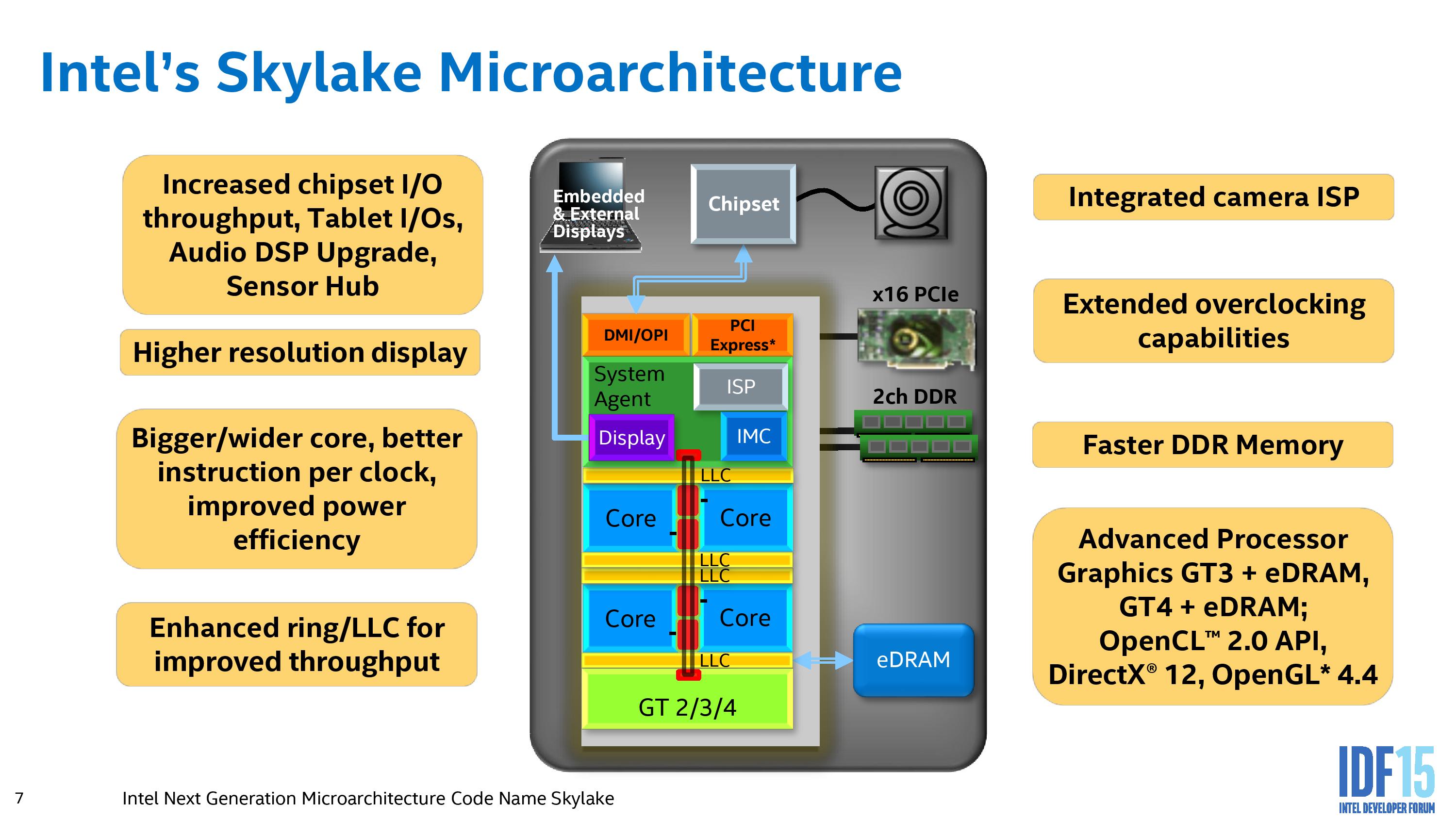
From most perspectives, the central image provided by Intel could have been taken from a Broadwell presentation if you scrubbed out the ‘GT4’ element of the design, but the move to Skylake suggests improvements in each of these areas either in terms of functionality, bandwidth, power consumption, or all of the above.
Out of the box, the Skylake IA core is designed to extract instruction level parallelism from code, and the design allows for more operations to be dispatched, queued and retired in a single clock. We cover this more in the next page. But to augment this, the data transfer ring between cores, cache, graphics and the system agent is also increased in read bandwidth to 128b, allowing more data to be supplied to the cores. In terms of the cores themselves, the big upgrades surround in-flight management of data, especially with respect to cache misses. We have been told that a number of these upgrades, while they might not be readily usable by current software, should have effects in certain vertical markets (finance, big data, etc).
From a memory connectivity standpoint, most processors will support both DDR3L and DDR4 with a dual memory controller design (or a single memory controller that supports both). Skylake-Y (Core M) is the exception here, and will only work in DDR3L/LPDDR3 modes. As always with multi-DRAM support designs, only one standard can be in use at any time.
On the PCI-Express Graphics allocation side, the Skylake-H and Skylake-K processors will have sixteen PCIe 3.0 lanes to use for directly attached devices to the processor, similar to Intel's previous generation processors. These can be split into a single PCIe 3.0 x16, x8/x8 or x8/x4/x4 with basic motherboard design. (Note that this is different to early reports of Skylake having 20 PCIe 3.0 lanes for GPUs. It does not.)
With this SLI will work up to x8/x8 and CrossFire to x8/x8 or x8/x4/x4 in both desktop and mobile designs. For desktops, if a motherboard supports x8/x4/x4 and a PCIe card is placed into that bottom slot, SLI will not work because only one GPU will have eight lanes. NVIDIA requires a minimum of PCIe x8 in order to enable SLI. Crossfire has no such limitation, which makes the possible configurations interesting. Below we discuss that the chipset has 20 (!) PCIe 3.0 lanes to use in five sets of four lanes, and these could be used for graphics cards as well. That means a motherboard can support x8/x8 from the CPU and PCIe 3.0 x4 from the chipset and end up with either dual-SLI or tri-CFX enabled when all the slots are populated.
For Skylake-U/Y, these processors are not typically paired with discrete graphics and as far as we can tell, the PCIe lanes have been removed from these lines. As a result, any storage based on PCIe (such as M.2) for devices based on these processors will be using the chipset PCIe lanes. As mentioned later, the chipsets on U/Y also differ to their more desktop oriented counterparts.
DMI 3.0
The Skylake-S and H processors are connected to the chipset by the four-lane DMI 3.0 interface. The DMI 3.0 protocol is an upgrade over the previous generation which used DMI 2.0 – this upgrade boosts the speed from 5.0 GT/s (2GB/sec) to 8.0 GT/s (~3.93GB/sec), essentially upgrading DMI from PCIe 2 to PCIe 3, but requires the motherboard traces between the CPU and chipset to be shorter (7 inches rather than 8 inches) in order to maintain signal speed and integrity. This also allows one of the biggest upgrades to the system, chipset connectivity, as shown below in the HSIO section.
Skylake-Y/H, by virtue of having the chipset on the processor package, can keep the interface between the CPU and IO very simple and uses what they call an OPIO – on package input-output. We have seen this as far back as Haswell to deliver 4GB/s of bandwidth at 1pJ/bit, and has been listed as being very power efficient as well as highly scalable.
CPU Power Delivery – Moving the FIVR
Moving on to power arrangements, with Skylake the situation changes as compared to Haswell. Prior to Haswell, voltage regulation was performed by the motherboard and the right voltages were then put into the processor. This was deemed inefficient for power consumption, and for the Haswell/Broadwell processors Intel decided to create a fully integrated voltage regulator (FIVR) in order to reduce motherboard cost and reduce power consumption. This had an unintended side-effect – while it was more efficient (good for mobile platforms), it also acted as a source of heat generation inside the CPU with high frequencies. As a result, overclocking was limited by temperatures and the quality of the FIVR led to a large variation in results. For Broadwell-Y, this also resulted in an increase for the z-height of the processor due to having leveling transistors on the rear of the package. As a result, in order to decrease the z-height of any corresponding product, a hole in the motherboard had to be forged:

For Skylake, the voltage regulation is moved back into the hands of the motherboard manufacturers. This should allow for cooler processors depending on how the silicon works, but it will result in slightly more expensive motherboards.
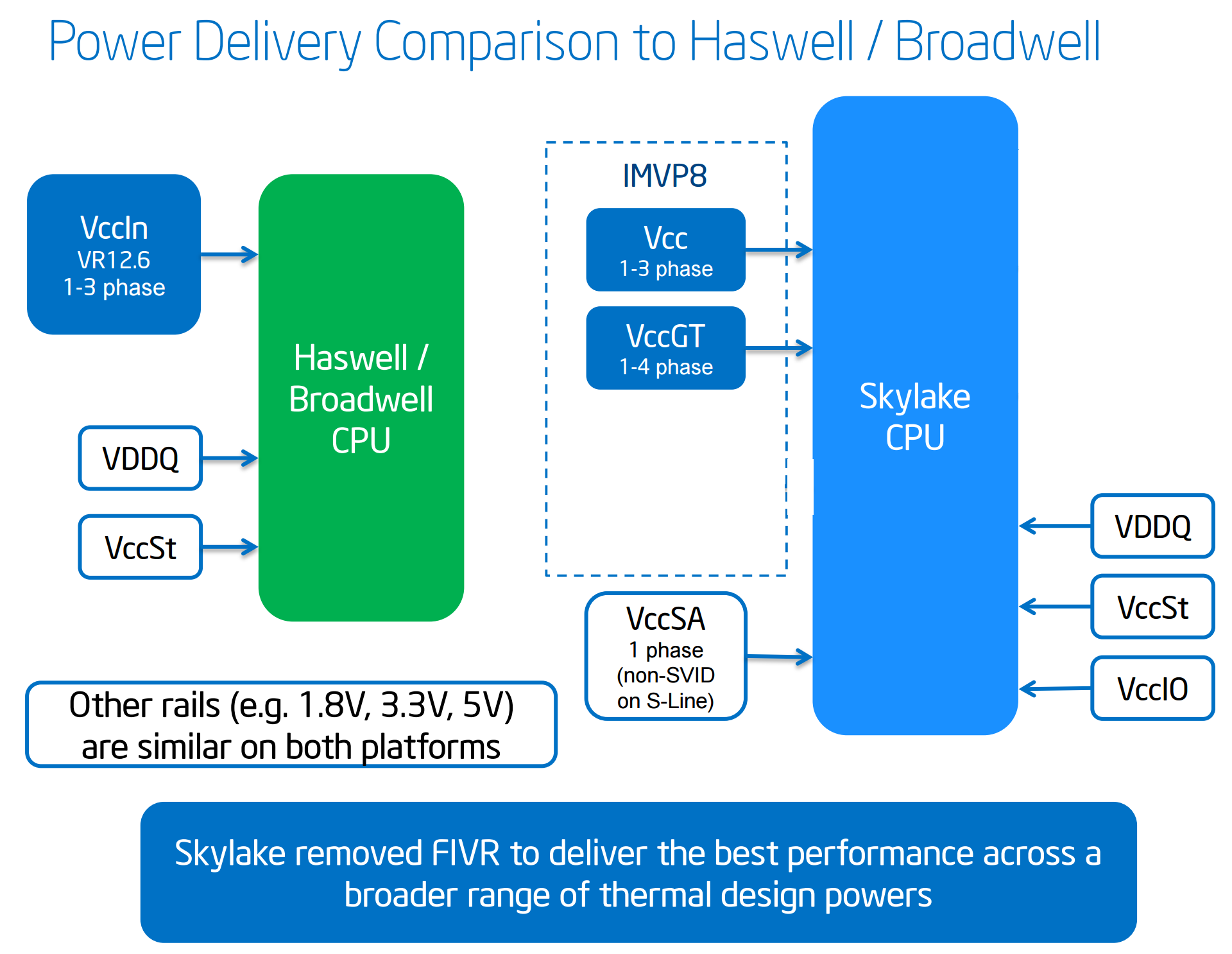
A slight indication of this will be that some motherboards will go back to having a large amount of multiplexed phases on the motherboard, and it will allow some manufacturers to use this as a differentiating point, although the usefulness of such a design is sometimes questionable.
A small portion of this page was posted as part of our initial Skylake-K coverage.
Sockets and Chipsets
The new Skylake-S processors are assigned a new socket, LGA 1151, while the soldered down models use a combination of BGA 1515 (Skylake-Y), BGA 1356 (Skylake-U) and BGA 1440 (Skylake-H). On the desktop, Intel’s policy since 2006 has been to maintain sockets for two generations and as a result moving from Broadwell to Skylake we were expecting the change. This means that Skylake processors will not work in LGA1150 based motherboards, i.e. those with Intel’s 8th and 9th generation chipsets. For Skylake we get the 100-series chipsets with additional functionality.
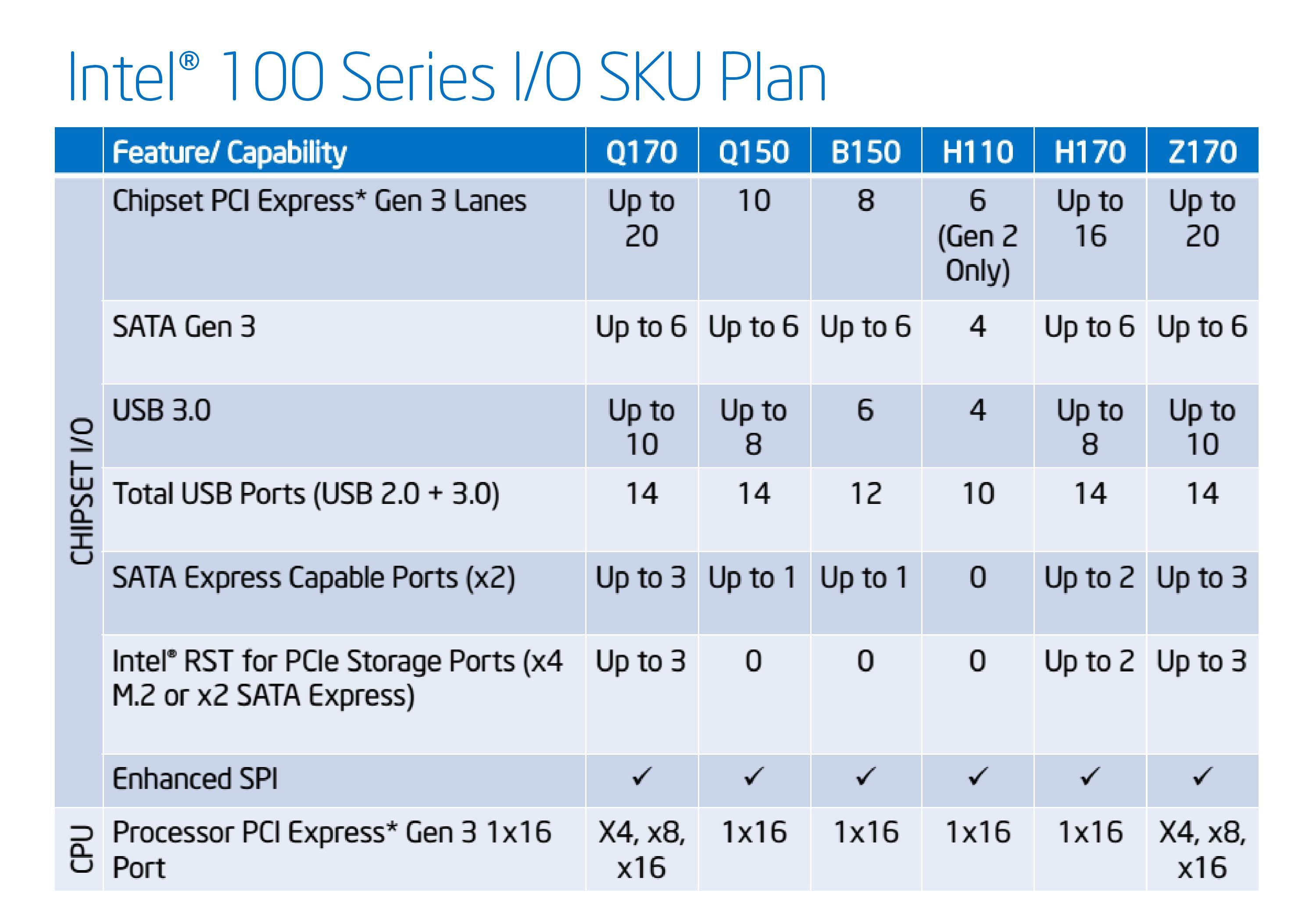
Both Skylake-S and Skylake-H will be subject to the list above, and as mentioned on the previous page while these are being announced today, the more business oriented models (B150/Q1x0) will have a slower roll out over the next few months.
It is worth noting that we had heard rumors that the Z170 chipset was going to be expensive for motherboard manufacturers, resulting in some motherboards that might cost more than X99 counterparts, although those fears were removed when Intel provided final pricing. Nevertheless, it means that there is scope for the cheaper chipsets with fewer features such as H170/H110, especially in high volume markets.
If we set aside the Q170 platform as being Z170 without overclocking but SMB/vPro support, going down in number means fewer features. Perhaps shockingly the H170 chipset is the only other chipset to support Intel RST on PCIe storage, but aside from that the segmentation is as expected with fewer chipset PCIe lanes available on the 150/110 lines.
We’ve touched on the number of chipset lanes on Skylake-S in previous articles, but the 20 PCIe lanes afforded by Z170 is essentially split into five x4 controllers. Each controller can be split into x1, x2 or x4 lanes to total up to four, with a few specific lanes set aside for various features. But the idea here is that the user no longer has to decide between things like M.2 or SATA Express or PCIe slots – with so many on offer, the combinations are somewhat endless.
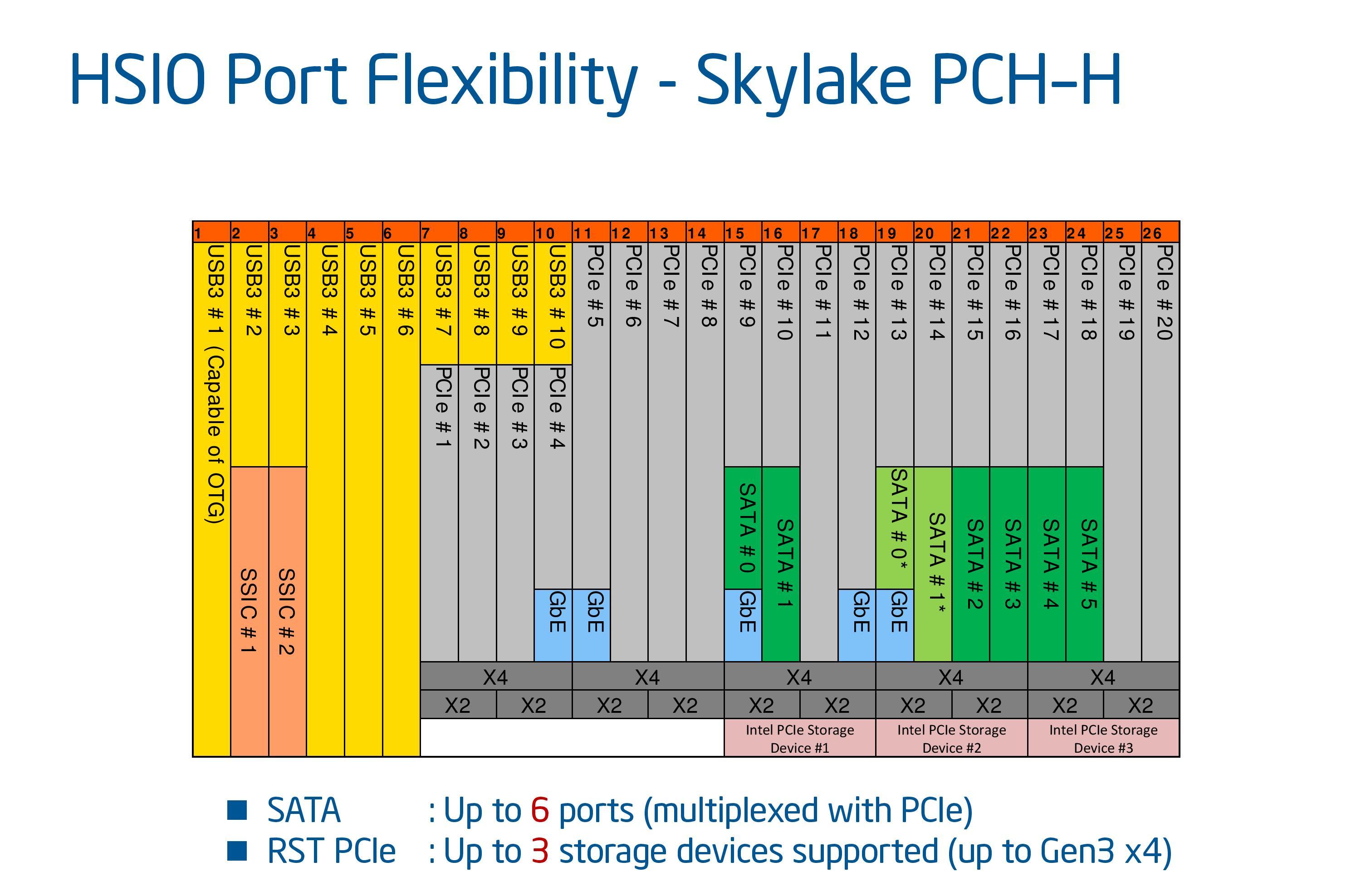
So in the Z170 and Skylake-H arrangements, three of these x4 controllers are specifically for PCIe storage in RST, however using them all would eat up all the chipset SATA ports, requiring some form of SATA controller if that functionality is wanted. There is also some limitations with gigabit Ethernet controllers as well. But apart from that, any feature that requires a PCIe controller can be added as required (USB 3.1, Thunderbolt, WiFi, non-RST PCIe storage, PCIe slots).
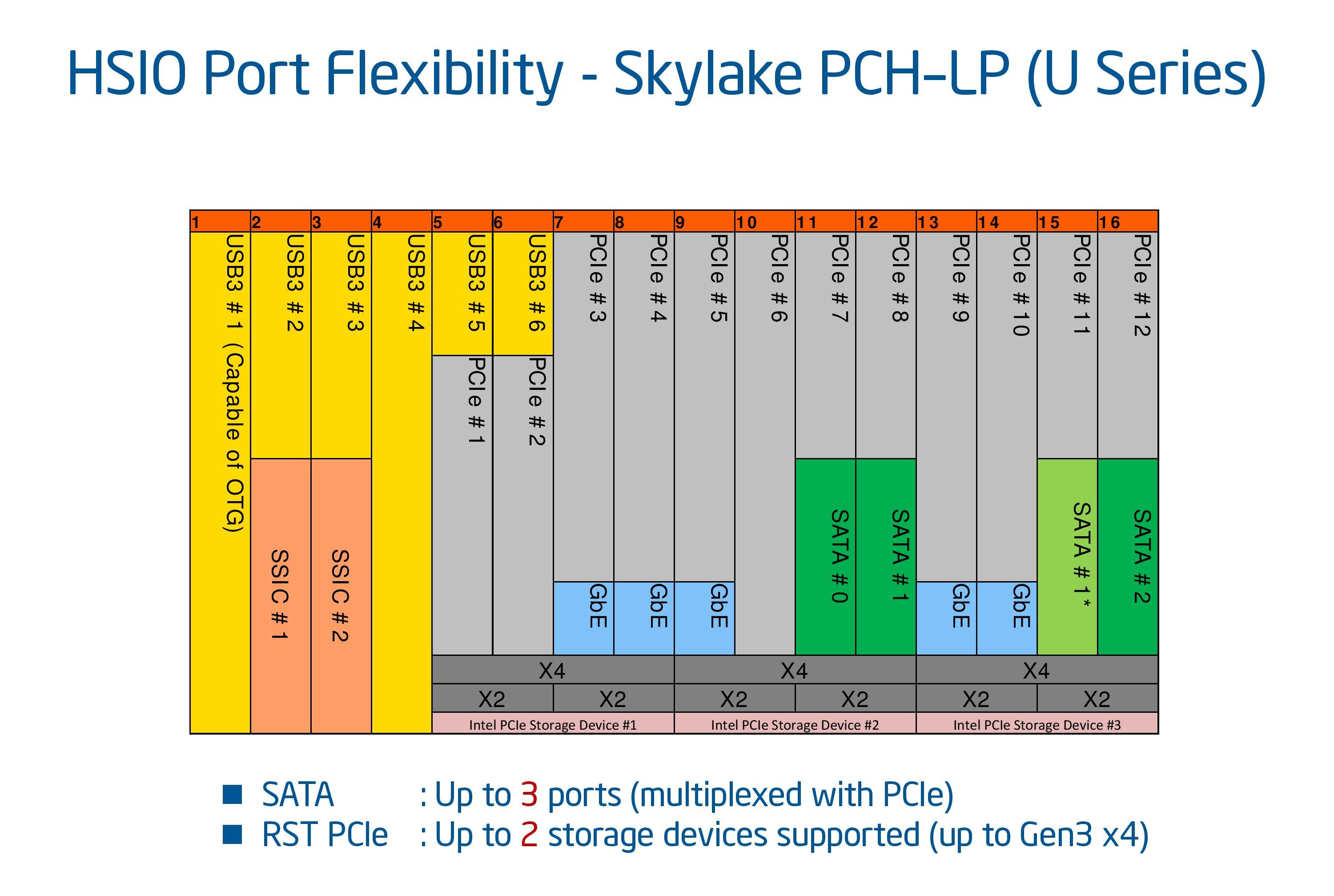
Because Skylake-U and Skylake-Y use on-package low power chipsets, there is a need to be a little more frugal when it comes to functionality in order to save power. As a result we get 12 PCIe lanes for Skylake-U but these can still be split for Intel RST.

Skylake-Y takes out another pair, and limits the onboard SATA ports to two. Interestingly enough, you could still have five native gigabit Ethernet controllers on there as well. I offer $10 and a drink to the first OEM to come up with a Skylake-Y + 5x GbE design.
We have a large piece on the desktop motherboards being released or talked about for Skylake, covering some 55+ products and the different variations within. The major motherboard manufacturers such as ASUS, GIGABYTE, ASRock, MSI, EVGA and a couple of others should all have a wide range ready to purchase on day one, although some models may be region specific.

The badly MSPaint’ed hybrid: MSI’s XPower Gaming Socket, GIGABYTE’s G1 Gaming IO panel, EVGA’s DRAM slots, ECS’s chipset, ASRock’s PCIe arrangement and ASUS’ Deluxe audio.
Here’s an amalgamation of some of the designs coming to end users, with almost all of them investing heavily in gaming brands with specific components to aid the user experience while gaming. Aesthetic designs are also going to be a focus of this generation, with some of the manufacturers moving into a different direction with their designs and trying some new color schemes. Some basic looking models will also be available.
Prices for motherboards will range from $60 all the way past $400+, depending on feature set and size. A number of motherboards above $150 will feature a couple USB 3.1 Gen 2 (10Gbps) ports, although you will have to check whether they are Type-A or Type-C. That being said, most motherboards with USB 3.1 will use both, but there are a select few that are C-only or A-only. We will see a lot of Intel’s new network controller, the I219-V, although the gaming lines might invest in Rivet Network’s Killer solution instead.
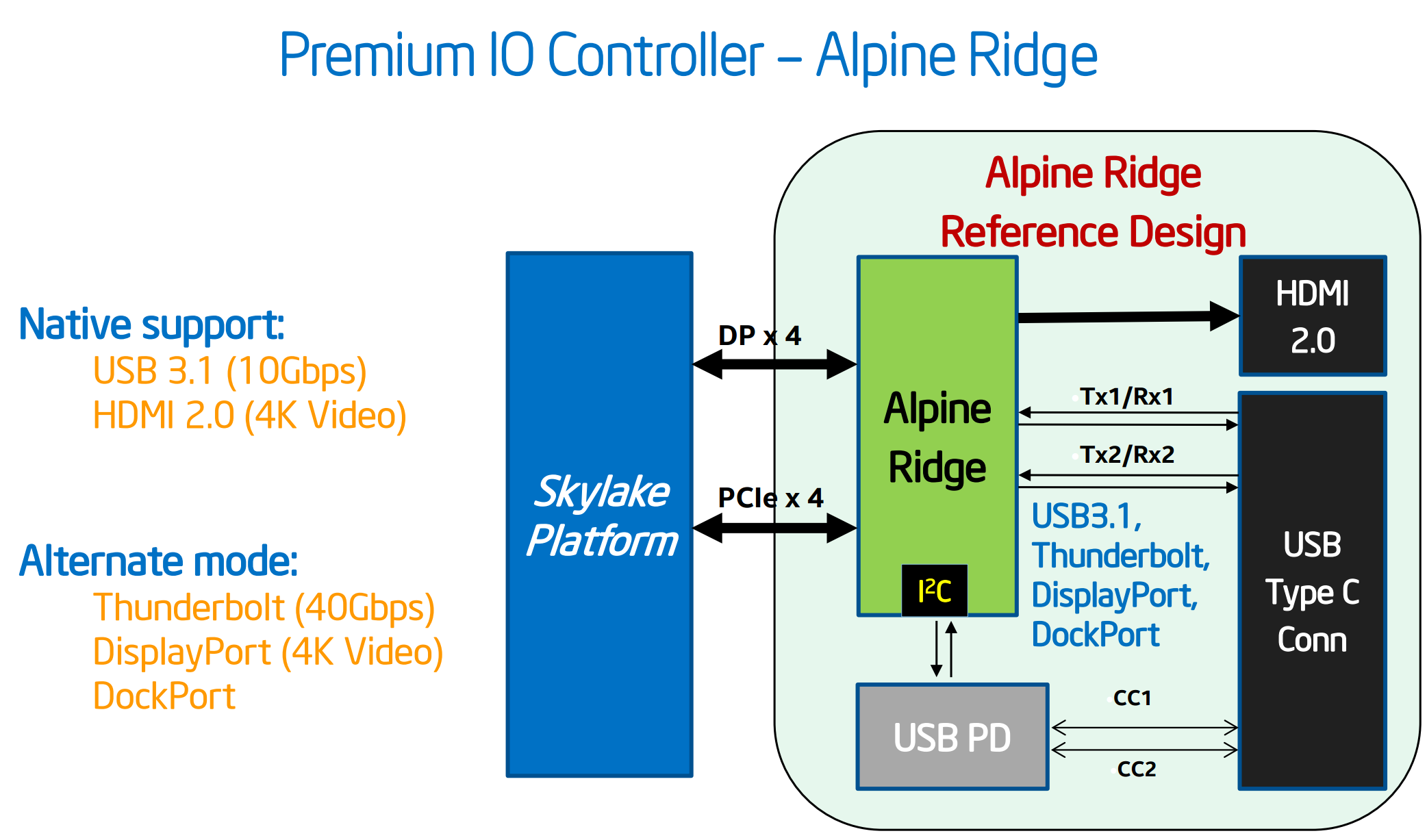
Thunderbolt obviously has more of a play in the laptop space here, and will be available through Intel’s Alpine Ridge controller. As far as we can tell no devices are set to be announced this week that will have TB support (though we might be surprised), but the controller can also be used for USB 3.1 Gen 2, HDMI 2.0, DisplayPort, and DockPort. According to our sources it would seem that GIGABYTE currently has an exclusive on this technology in the desktop space, and it will be used for their USB 3.1 Gen 2 ports on most motherboard models. The other functionality from the Alpine Ridge controller (TB3, HDMI 2.0) will be on a case-by-case basis depending on how the controller works in two different modes or if extra components are used. We are told that Alpine Ridge costs similarly to the ASMedia ASM1142 controller, but will enable two USB 3.1 Gen 2 ports at 10 Gbps simultaneously as it uses four PCIe lanes from the chipset.
DRAM: The March to DDR4
In the world of DRAM for personal computers, DDR3 is currently king. Having been the main standard since 2007, you would be hard pressed to find a mainstream or low end platform sold that did not require access to DDR3. That changed in the enthusiast segment last year with the launch of Haswell-E which also introduced DDR4 at a high premium. For Haswell-E there was no crossover – you had no choice but to use DDR4 (unless you might be a million-unit customer).
Because the consumers and consumer product OEMs are more price sensitive, DDR4 will be a slower transition in desktops, but the uptake in laptops should be more down to availability. For example, we have seen some DDR4 SO-DIMM engineering samples, but right now we are unsure as to how many of these are available on the B2B circuit as very few (if any) has filtered down to consumer.
Note that there is precedent here in that the move from DDR2 to DDR3 saw a generation of processors that supported both standards and it was up to the motherboard manufacturer to design for it. In this transition, most Skylake processors will support both DDR3L and DDR4 modules, with a few caveats.

On the desktop side, caveat number one is that initially, only DDR4 motherboards will be on the market. So if you upgrade now, DDR4 needs to be on the shopping list as well. We have had word of some DDR3L-only motherboards coming, especially now that the B/H chipsets are beign released. Combo boards with DDR3L and DDR4 slots on board are also inbound, but caveat one-point-five - you can use either DDR3L or DDR4 but not both at the same time.
Caveat number two, DDR3L is different to DDR3 as it operates at a lower voltage. This means that the memory controllers on Skylake most likely have a combined voltage domain, and regular DDR3 might not work (in fact early testing suggests not without reducing the voltage). Very few people currently own DDR3L DIMMs, so the likelihood of a user performing an upgrade while reusing their RAM might be slim.
Caveat number three: prices of DDR4 have dropped significantly since last year, and there is only a small premium over DDR3. The benefits of DDR4 include a lower operating voltage, a more stable design, and the ability to purchase 16GB modules with ease. That means that a Skylake-S platform will happily take 64GB of memory. Should 16GB SO-DIMM modules surface, we assume Skylake-H designs should be able to use 64GB also.

With that last point, we should point out that Skylake is a dual memory channel architecture, supporting two memory modules per channel. This gives a maximum of four DDR4 tests, and 4x16 = 64GB maximum. We have been told that Skylake’s DDR4 memory controller, compared to previous generations, is absolutely golden at higher speed memory support. By default Skylake supports the JEDEC standard for DDR4, 2133 MT/s at a latency of 15-15-15, but the overclocking guides we have received suggests that all processors should be able to reach DDR4-3200 relatively comfortably, with a few processors in the right motherboards going for DDR4-4000. While this should bode well for integrated graphics users, those high end kits are typically very expensive.
If you read our review of the Skylake-K processors, you will note that in terms of clock-for-clock performance, Skylake was not as big of a jump as people were perhaps expecting, affording an average of 5.7% over Haswell and 2.7% over Broadwell. For an architecture change, users (us included) have come to expect a 5-10% generation on generation increase at the same frequency. So by getting these results, we started to point some fingers and questions at Intel regarding the architecture due to the fact that in a change from previous launches this information was to be provided post-launch. That time was IDF, and while Intel did get somewhat technical, there are still some questions hanging in the air. In the meantime, this is what we learned. For this page, we’re focusing purely on performance, with power considerations a few pages further on.
Do More On The Fly
There are many different metrics and underlying on-paper ways to increase performance. Being able to process commands and data in fewer cycles, or by handling/processing more data at once, are two very important ones. Intel tries to tackle both within the out-of-order architecture.

Instruction level parallelism is one of the holy grails in processor design – if you are able to separate a set of code into X instructions and process all X at once (due to a lack of dependencies), then the problem is cracked. The downside is that a lot of code and as a result, a lot of instructions, rely on other instructions and data. The best bit about an out-of-order architecture is that when many different branches of code and instructions are in flight at once, they can be grouped up in the scheduler and a level of instruction parallelism can be achieved.
So first up is the OoO window, increasing 16.7% over Haswell. This allows the micro-ops (Intel’s version of deconstructing the instructions) to fill the queue and be arranged such that more parallelism can take place. This also takes advantage of in-flight loads and stores such that data can be available by the time the micro-op gets to the front of that queue. The idea is that heavy workloads that are interchangeable but require data access stalls can take advantage and hide the latency associated with those stalls, as well as allowing certain operations to be fused in order to reduce the workload.

With the micro-ops, Intel has upgraded the front end of the IA core to allow a dispatch of six micro-ops at once, up from four on Haswell. This allows the queue to be quicker, but also the dispatch of micro-ops from the queue to the execution units has increased to six also. Note that the execution units are limited by the number of INT/FP/Load/Store available, so it is the job of the queue to reorder the micro-ops to take advantage of this, as well as manage the memory accesses.
The front-end (uOp allocation and up) is designed to take advantage of better branch prediction and faster prefetch, as well as the increased in-flight buffers as mentioned above. Branch prediction is also another element to increasing processor performance here – in some circumstances the CPU will speculate as to the instruction required and then dump the result it doesn’t need. Too much speculation wastes power, but not enough will result in increased processing time and latency. So the branch predictor acts as a secret sauce for a lot of core design, but we are told that Skylake improves this.
On the front end, there are some small adjustments in the execution units with regards latency – the divider is improved, which is normally a difficult set of commands to optimize and calculated via an improved radix. Typically when writing scientific calculation code for example, it is often suggested to minimize divisions where possible. On the other side of the coin, the FMUL (floating point multiply) has increased in latency over Broadwell, and returned to the same as Haswell. We are told that this is due to design decisions that allows for better performance when it comes to creating enterprise silicon, which is an interesting explanation in itself. The execution units also have a greater degree of granularity in their power modes, allowing those not active to save power.

One element we did not mention in our original Skylake review (because we didn’t notice, I’ll be honest), is that the L2 cache on Skylake is reduced from an 8-way associative cache to a 4-way model. This is odd for Intel, given that as far back as Sandy Bridge, they have always worked with an 8-way L2. In real world terms, this relates to how the L2 data is stored and accessed, where a doubling in the associativity often reduces the miss rate depending on the algorithm. However, reducing the associativity saves power on data accesses that are successful and in some circumstances can also save area on the silicon die. So by moving from 8-way to 4-way, Intel saves some power with Skylake but loses some performance if you compare two identical silicon models. Intel counters this move by saying that the bandwidth to the L2 cache misses is doubled, as well as improving how cache and page misses are handled providing a lower latency for that data. The end result should be performance similar to that in Haswell, but at a lower power. We were also told that this has benefits when designing the server processor line, although we will have to wait and see exactly why.
Another element to the back-end results in improved HyperThreading performance. In our benchmark data we have seen this, where for example the ratio of Cinebench single threaded performance to multi-threaded performance was better than previous generations. Part of the HT improvements relate to micro-op retirement – basically being able to abandon used operations and free up the execution queue. When I heard this, my first question was if instruction retirement was ever a bottleneck – would you ever be in a position where you have all the data you need to process an instruction but because the older instruction is not cleared, the new instruction cannot be processed? Apparently the answer is yes, and the new design allows each thread in a core to retire four micro-ops in one cycle. This should mean that HyperThreading yields some tangible benefits when it comes to intensive workloads (again, another nod to the enterprise performance crowd).
Ultimately, from a pure core design point of view, Skylake looks a lot like Haswell with minor tweaks that are not instantaneously obvious. It can be hard to feel how ‘a deeper buffer’ can increase performance when the software being used barely filled the buffer in the first place. A lot of these improvements are aimed directly at the pure-performance perspective (except L2 and FMUL to an extent), so you really have to be gunning it or have a specific workload to take advantage.
It is at this point I should mention that Intel's policy of disclosing new architecture details seems to hold back more and more details each generation, such as pipeline length, branch misprediction penalties and exact adjustments to instruction throughput. For example, the FMUL adjustment in latency was only found when we asked about it based on a rumor we had heard. It seems that Intel might be willing to give the information if specific questions are asked, although other information needs to be investigated.
A side note on the enterprise based comments. In the first slide of the core front/back end, it states ‘dedicated server and client IP configurations’. As far as we can tell, this is a drive to make Intel’s processor/core designs more modular in nature such that being able to produce a custom processor for a certain enterprise market is easier to do. That being said, designing a core and working within design constraints can be a pain (you want registers and caches to be close to the queues to be close to the execution units and so on), so some optimization in a modular system still has to be made. It also makes us wonder to what level the modularity can take, and if some of the more esoteric designs might help Intel develop custom SoCs similar to AMD. It’s a thought.
Security Technologies
Along with the core upgrades, Intel is introducing both SGX (Security Guard Extensions) and MPX (Memory Protection Extensions) to Skylake.

This is in part similar to ARM’s TrustZone, or sandbox modes, whereby a program can be run in its own environment (or enclave is what Intel calls it) where it cannot interact outside the enclave and any attempt by other programs to access the memory in which it resides fails.

The MPX implementation is to aid buffer overflow errors that are a common source of security breaches.





eDRAM Changes
Until testing Broadwell-H and meeting up with certain individuals at IDF, the principle of the eDRAM Intel had been using was a little ill-defined. Sure we tested it when it launched, as well as the Broadwell processors, and commented that the obvious tasks to be improved came down to gaming on integrated graphics or very specific workloads. For Skylake, eDRAM enabled processors will be configured differently to previous versions in order to make the effect of the eDRAM more seamless for software.
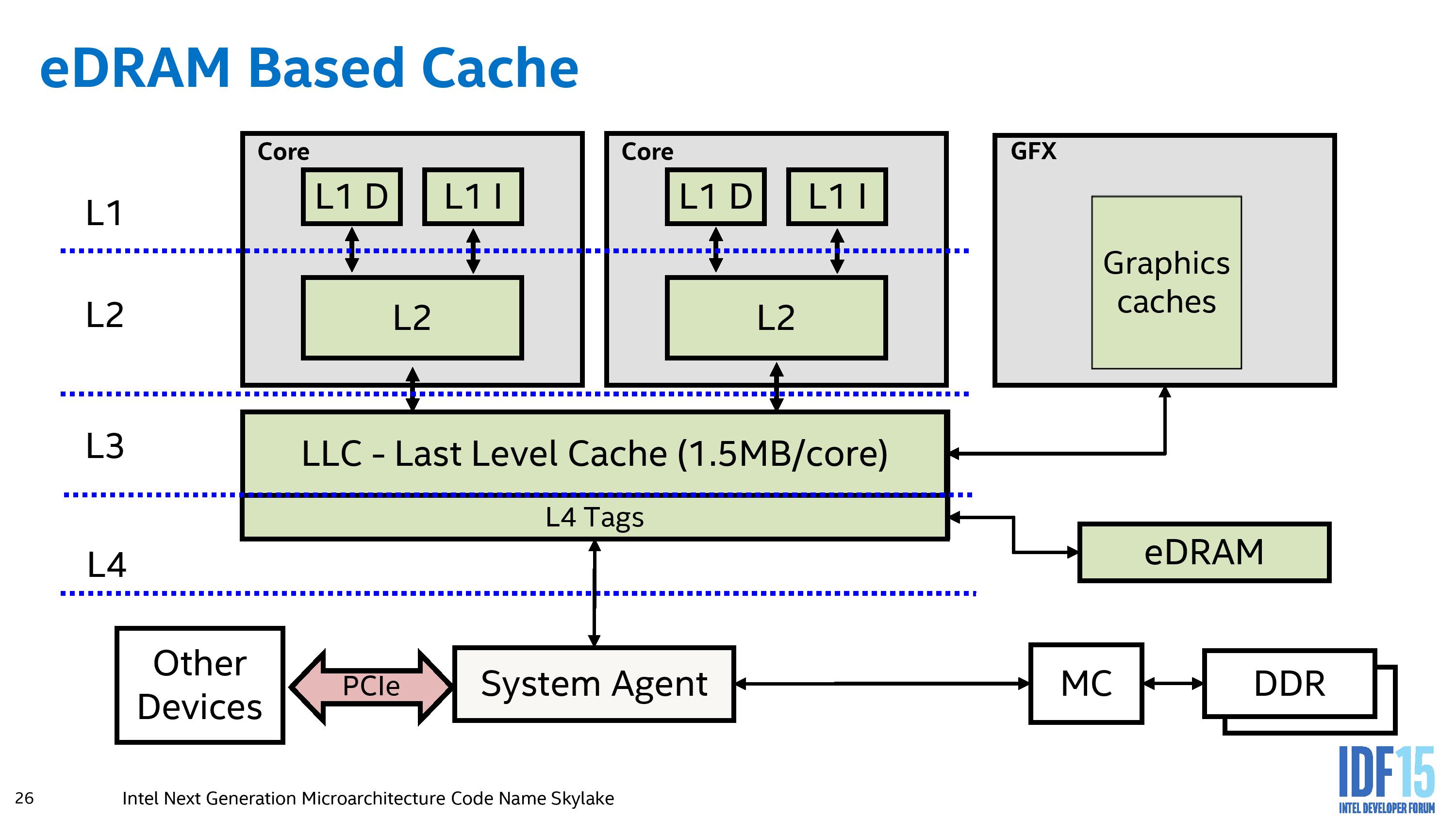
This is the current eDRAM representation for Haswell and Broadwell processors. Here we see that the eDRAM is accessed by a store of L4 tags contained within the LLC of each core, and as a result acts more as a victim cache to the L3 rather than as a dynamic random access memory implementation. Any instructions or hardware that requires data from the eDRAM has to go through the LLC and do the L4 tag conversion, limiting its potential (although speeding up certain specific workloads by virtue of a 50 GB/s per-link bi-directional interface.
In Skylake, the eDRAM arrangement changes:
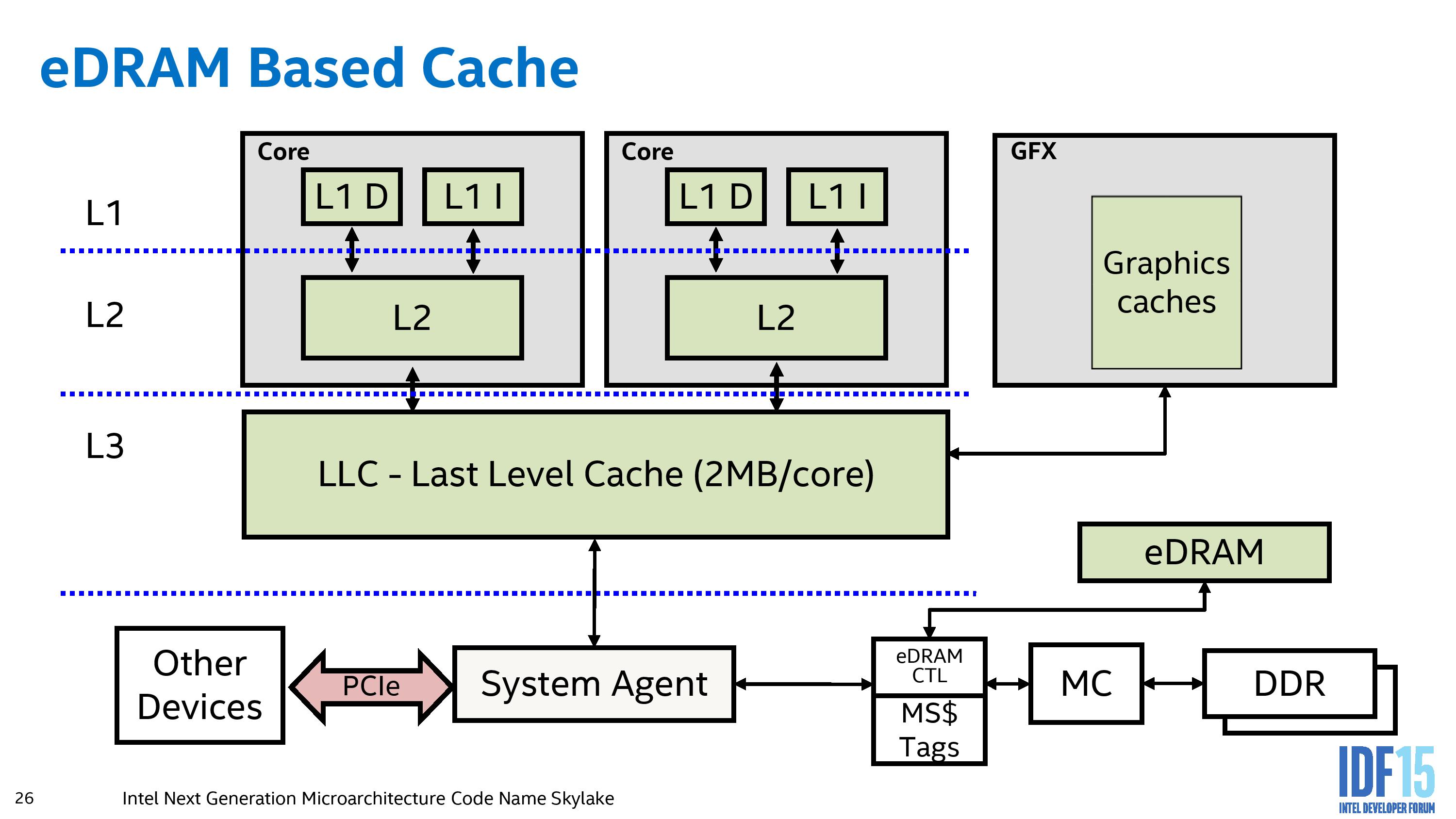
Rather than acting as a pseudo-L4 cache, the eDRAM becomes a DRAM buffer and automatically transparent to any software (CPU or IGP) that requires DRAM access. As a result, other hardware that communicates through the system agent (such as PCIe devices or data from the chipset) and requires information in DRAM does not need to navigate through the L3 cache on the processor. Technically graphics workloads still need to circle around the system agent, perhaps drawing a little more power, but GPU drivers need not worry about the size of the eDRAM when it becomes buffer-esque and is accessed before the memory controller is adjusted into a higher power read request. The underlying message is that the eDRAM is now observed by all DRAM accesses, allowing it to be fully coherent and no need for it to be flushed to maintain that coherence. Also, for display engine tasks, it can bypass the L3 when required in a standard DRAM access scenario. While the purpose of the eDRAM is to be as seamless as possible, Intel is allowing some level on control at the driver level allowing textures larger than the L3 to reside only in eDRAM in order to prevent overwriting the data contained in the L3 and having to recache it for other workloads.
As noted in the previous pages, the eDRAM from Intel will come in two flavors – 64 MB and 128 MB, which is different to the 128 MB only policy for Haswell and Broadwell. Back when Intel was discussing eDRAM before this, it was noted that Intel considered 32 MB ‘enough’, but doubled it and doubled it again just to make sure the system truly saw some benefit. It seems that for some circumstances (or some price points for that matter) 64 MB is felt as a better fit in that regard, given that Intel believes that its initial design had plenty of headroom. As far as we can tell, eDRAM will be available in 64MB for GT3e and 128MB for GT4e configurations (48 EUs and 72 EUs respectively), although we might see some variation as time goes on. We have confirmed with Intel that the 64 MB implementation is a half-silicon implementation (rather than a disabled full-silicon), but the bandwidth to the system agent is the same in both circumstances.
A number of media have already been requesting an announcement regarding a discrete processor with an eDRAM implementation, similar to Broadwell. I even enjoyed conversations at IDF where it was suggested that Intel could produce an i7 at 4.0 GHz with 128MB eDRAM, either with or without overclocking, and charge a nice $30-$50 premium for it. However, we were told that a quad core desktop part with eDRAM (either 4+2e or 4+4e) is currently not POR, which means ‘plan of record’. To avoid confusion, because technically a 3+2 is not on their ‘plan of record), having been mentioned as not POR means means that Intel has looked at it as an option but at this time has not decided to release it at this time - if they ever will is another question to ask Intel. For users who actively want an LGA1151 4+4e configuration, make sure your Intel representative knows it, because customer requests travel up the chain.
Intel’s Generation 9 Graphics
On the graphics side of the equation, the information comes in two loaded barrels. For the media capabilities, including information regarding Multi Plane Overlay, Intel’s Quick Sync and HEVC decode, head on over to Ganesh’s great one page summary. Some of that information might be reproduced on this page to help explain some of the more esoteric aspects of the design.
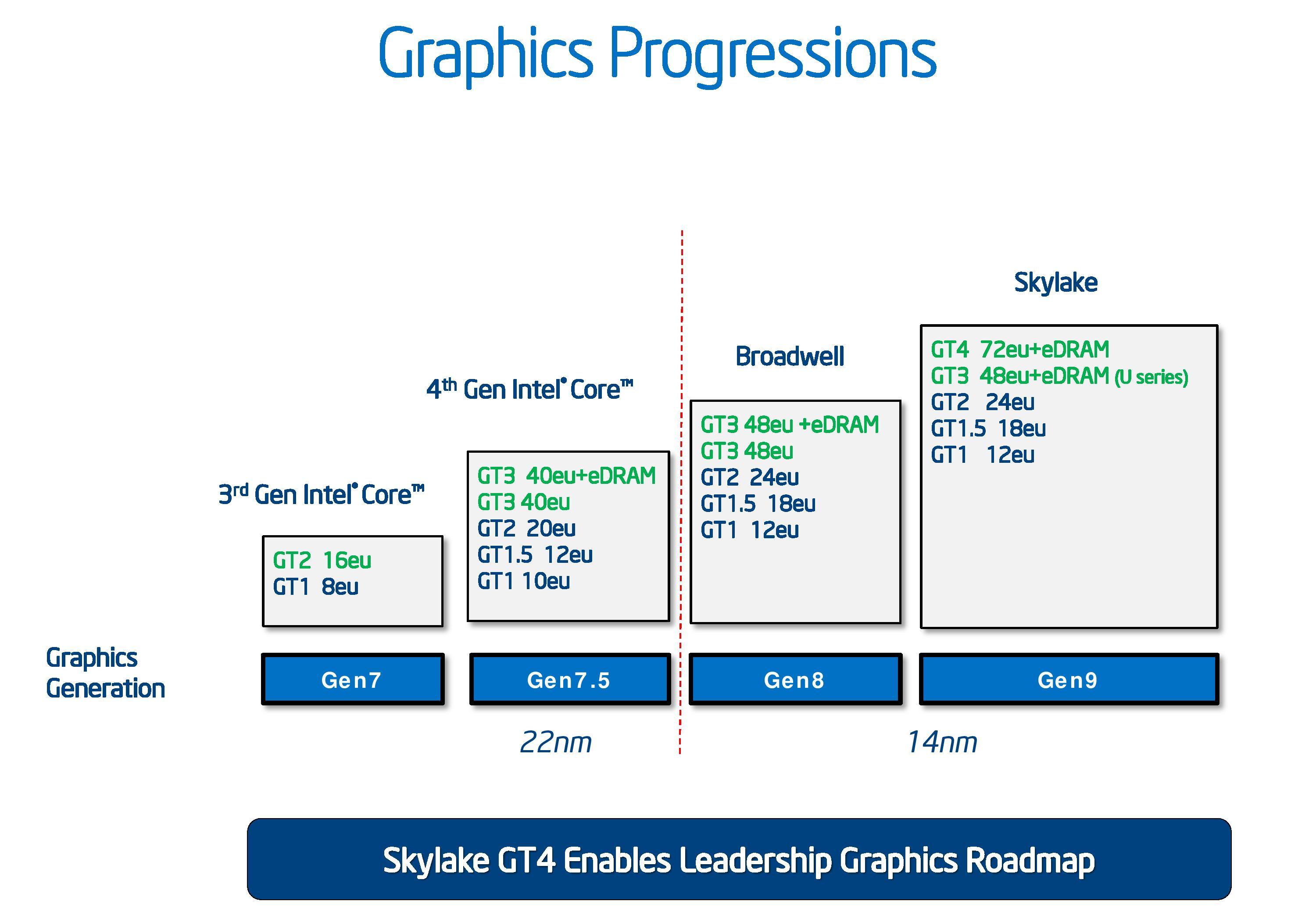
First let us look at how Intel’s integrated graphics has progressed over the generations. It has been no secret that the drive to integrated graphics has eaten almost all of the low end graphics market save one or two cards for extra monitor outputs. For Intel, this means slowly substituting a larger portion of the die to more execution units, as well as upgrading how those units process data. From the graphics above, and as we’ve noted before, Gen9 takes Gen8’s concept but with an added element at the top – GT4, which incorporates a new slice of EUs. As mentioned on the previous page, the eDRAM will come in 64 MB arrangements for GT3e (Iris), and 128 MB for GT4e (Iris Pro).
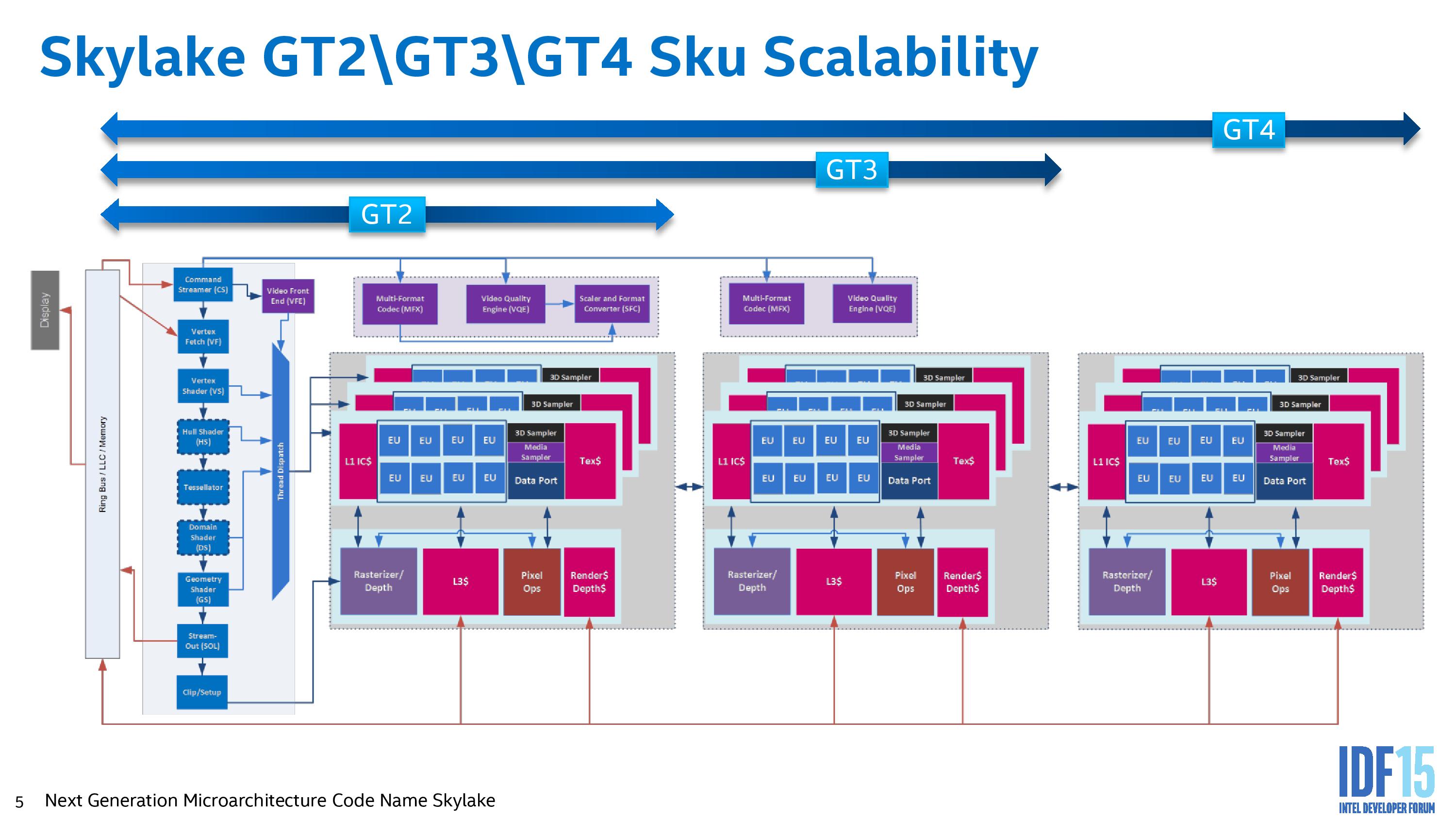
Intel’s graphics topology consists of an ‘unslice’ (or slice common) that deals solely with command streaming, vertex fetching, tessellation, domain shading, geometry shaders, and a thread dispatcher. This is followed up by either one, two or three slices, where each slice holds three sub-slices of 8 EUs, separate L1/L2/L3 caches and rasterizers, texture caches and media samplers. With one slice, a GT2 configuration of 24 EUs, we get the video quality engine (VQE), scalar and format converter (SFC) and a multi format codec engine (MFX). Moving to GT3 adds in another MFX and VQE.
| Intel Gen9 HD Graphics | |||||
| GPU Designation | Execution Units | GT | eDRAM? | YUHS | Example |
| Intel HD Graphics | 12 | 2+1 | - | Y | 4405Y |
| Intel HD Graphics 510 | 12 | 2+2 | - | U S | G4400 4405-U |
| Intel HD Graphics 515 | 24 | 2+2 | - | Y | 6Y75 6Y57 6Y30 |
| Intel HD Graphics 520 | 24 | 4+2 2+2 |
- | U | i7-6600U i3-6100U |
| Intel HD Graphics 530 | 24 | 4+2 2+2 |
- | H S | i7-6700K i3-6100T i7-6820HK |
| Intel HD Graphics P530 | 24 | 4+2 | - | H | E3-1535M v5 |
| Intel Iris Graphics 540 | 48 | 2+3e | 64MB | U | i7-6650U i5-6260U |
| Intel Iris Graphics 550 | 48 | 2+3e | 64MB | U | i7-6567U i3-6167U |
| Intel Iris Pro Graphics 580 | 72 | 4+4e | 128MB | H | - |
In each of the SKU lists, Intel has both the name of the graphics used as well as the base/turbo frequencies of the graphics. To synchronize both the name and the execution unit arrangement, we have the table above. At this point we have no confirmation of any parts having the GT1.5 arrangement, nor are we going to see any 23/24 EU combinations for Pentium/Celeron models similar to what we saw in Haswell. For the 12 EU arrangements, this means that these have a single slice of 24 EUs, but half of them are disabled. We questioned Intel on this back with Haswell, regarding of the EU cuts are split to 4/4/4 from the 8/8/8 sub-slice arrangement, and the answer we got back was interesting – there is no set pattern for 12 EU arrangements. It could be 4/4/4, or 3/4/5, or 3/3/6, or any other combination, as long as the performance is in line with what is expected and the EU count per sub-slice cannot be user probed. Despite the fact that a 3/3/6 arrangement might have L2 cache pressure in some circumstances, Intel feels that at this level of performance they can guarantee that the processors they ship will be consistent. It’s an interesting application.
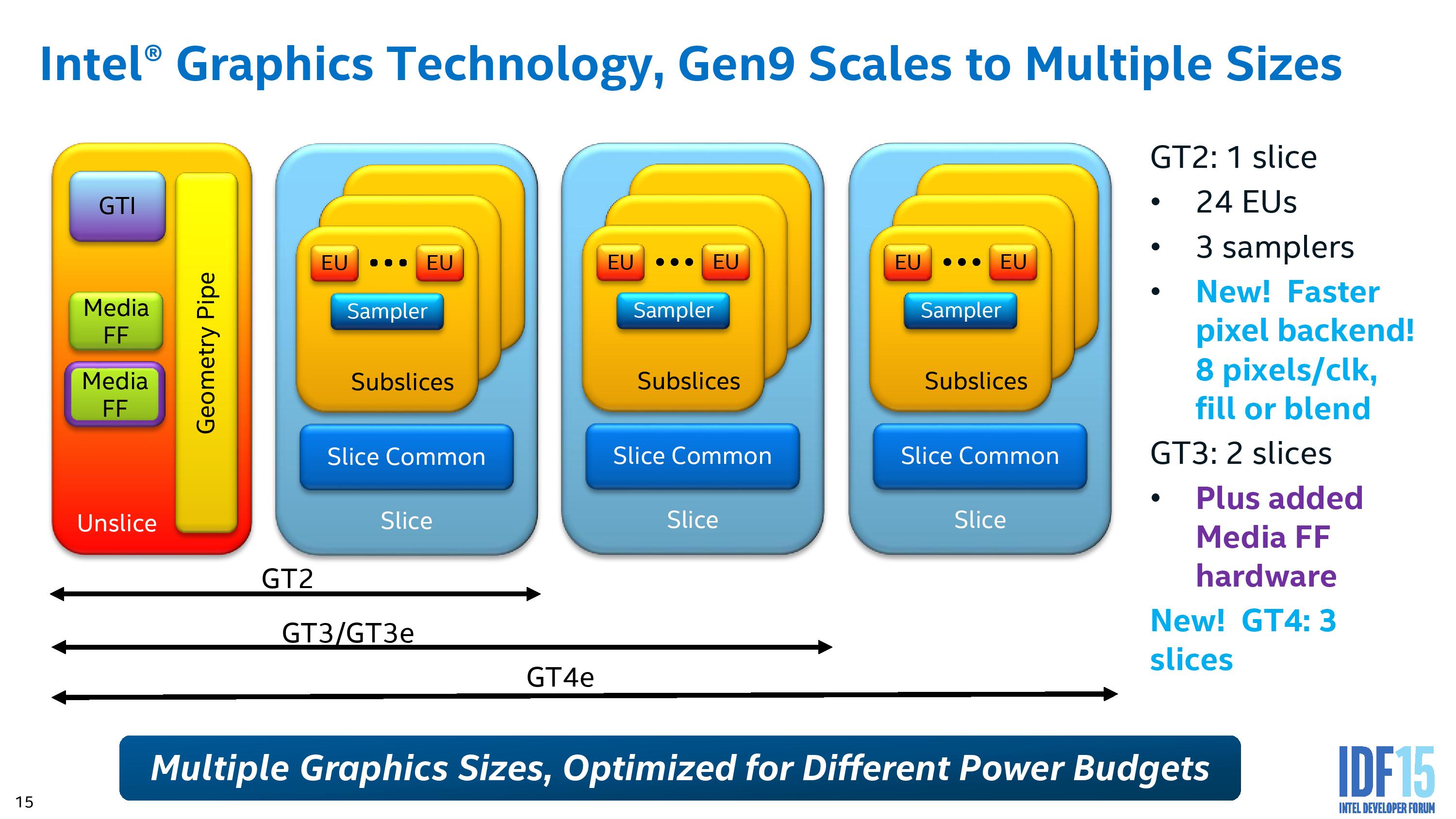
Part of Intel’s strategy with the graphics is to separate all of these out as much as possible to different frequency planes and power gating, allowing parts of the silicon to only be powered when needed, or to offer more efficiency for regular use cases such as watching video.
The geometry pipe in the un-slice is improved to improve the triangle cull rate as well as remove redundant vertices, which aids an improved tessellated that creates geometry in a format (tri-stips) that can be resubmitted through the triangle cull when needed.

As we noted at Skylake-K launch, Gen 9 graphics also features lossless image compression allowing for fewer data transfers across the graphics subsystem. This saves both power and bandwidth, and an upgrade to the display controller allows the image format to be read in a compressed format so as not to uncompress it before it gets sent out to the display.
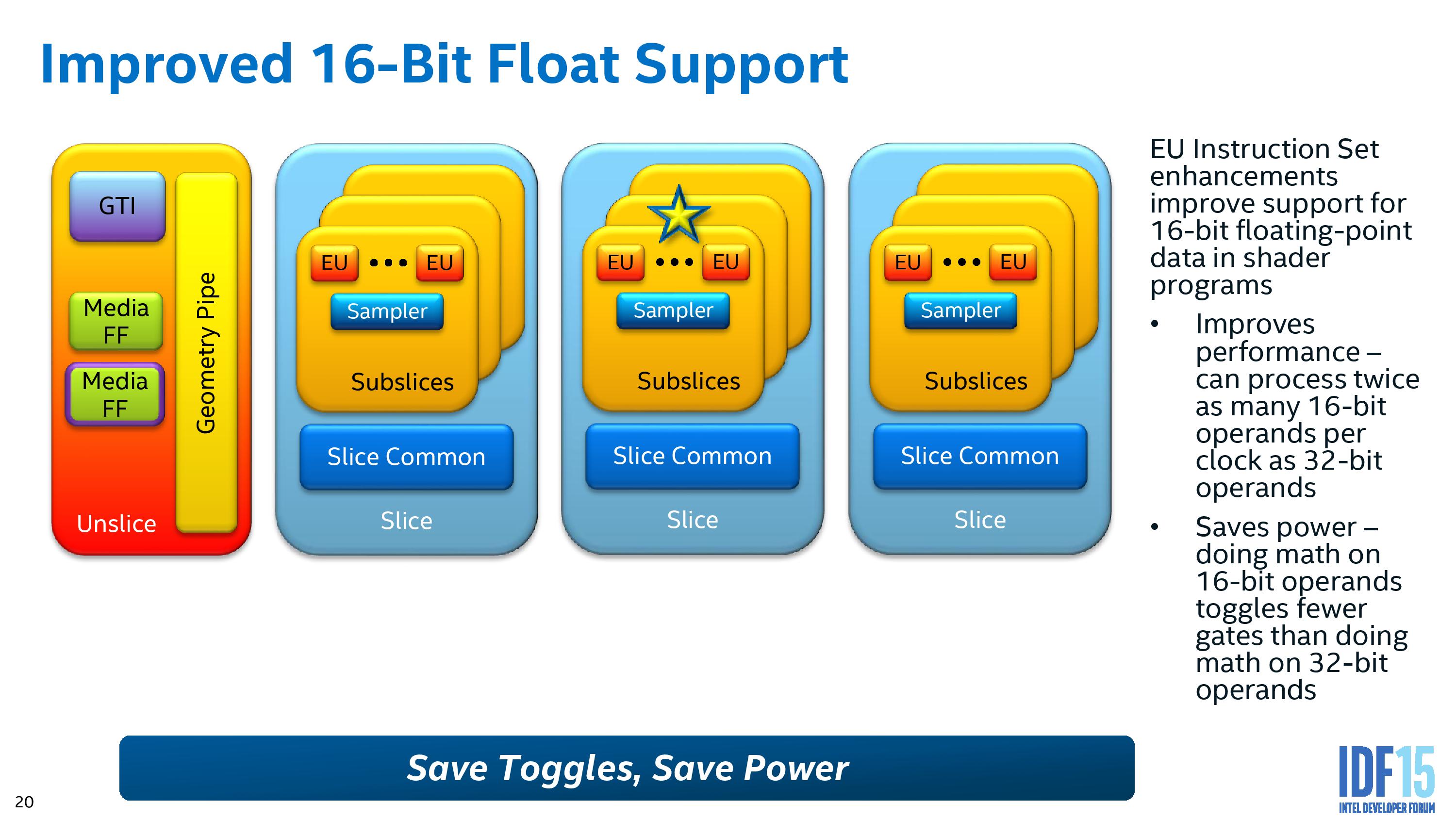
16-bit support has been a key element to discrete graphics in 2014 and 2015, affording faster processing when less accuracy is required by dumping extra significant digits. This is doubly beneficial, resulting in less power consumption for the same amount of work – Intel is exposing this to a greater degree in Gen9 for its shaders.
Intel’s big push on power for low-power Skylake is part of the reason why we did not see much difference in our Skylake-K review. Being able to shut off more parts of the processor that are not in use allows the available power budget to be applied to those that need it, hence why both power gating and frequency domains on the silicon, while they take up die area to implement, contribute to power saving overall or allow work to complete quicker in a race to sleep environment.
Multiplane Overlay (MPO)
One of the features I’m most particularly interested in is Multiplane Overlay. In a typical environment, a user might be looking at content that is stretched, rotated or distorted in some way. In order to perform this transformation, the image information is loaded into memory, siphoned off to the graphics to perform the mathematics, moved back into memory and then fired off to the display controller. This in and out of the DRAM costs power and battery life, so an attempt to mitigate this with fixed function hardware is ultimately beneficial. This is what MPO does.
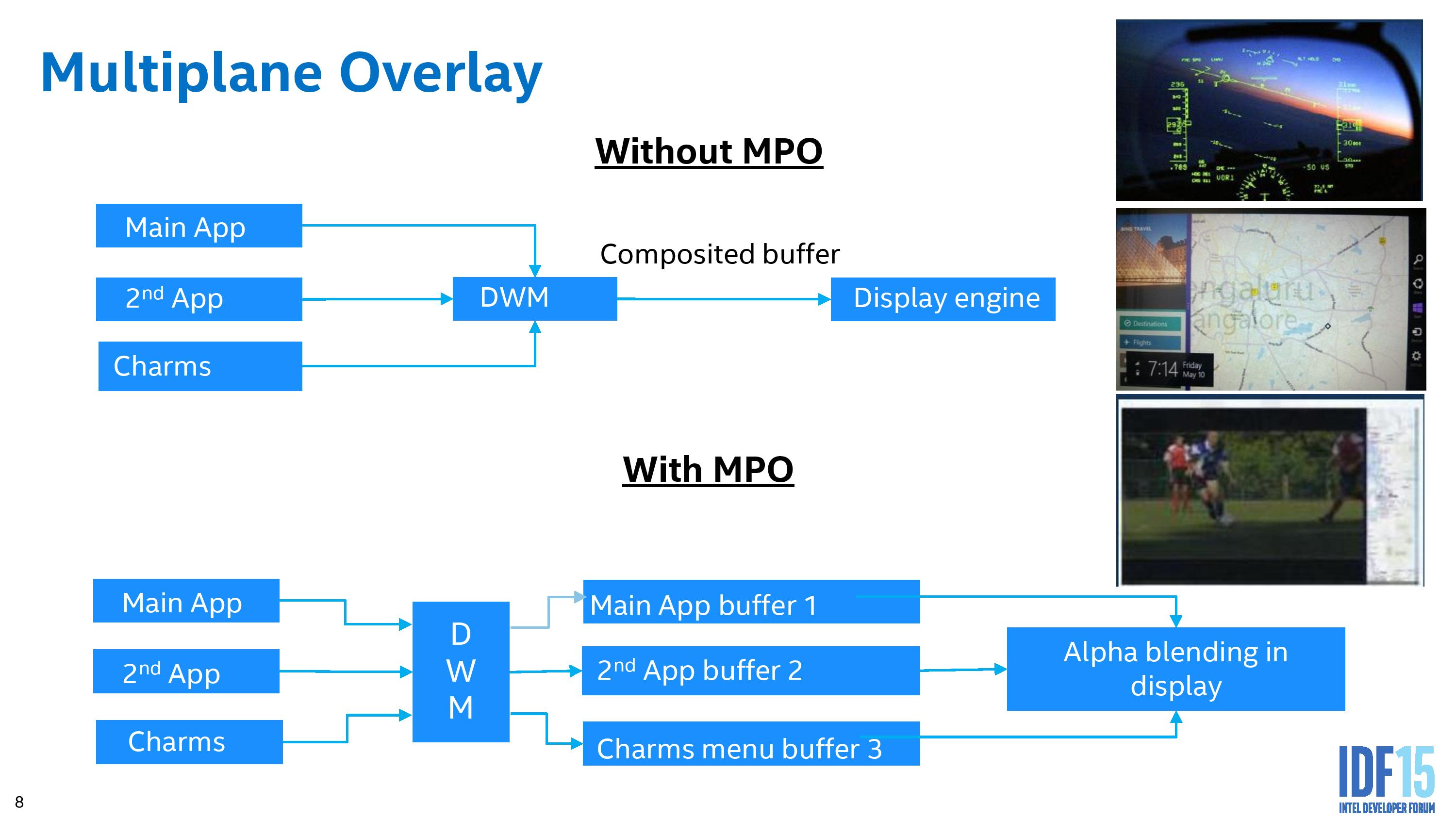
This slides shows a good way on how MPO works. The current implementation splits the screen into three ‘planes’ (app, background, cursor, or any combination therein) which are fired off to the desktop window manager (DWM). In a standard method, these layers are worked on separately before being composited and sent off to the display (the top model). With MPO, each of the planes fills a buffer in fixed function hardware on the display controller, without touching the GPU and requiring it to be put into a high power mode. MPO also allows for data in NV12 format to be processed on the fly as well, rather than requiring it all to be RGB before it is recombined into the final image (which again, saves power and bandwidth).
There are some limitations to this method. Currently, only three planes are supported, and there is no z-hierarchy meaning that if an app is obscured by another but still requires work, and then it does not get discarded as it should. For non-OS work that takes full-screen environments, it also requires the necessary hooks to the FF hardware otherwise it will assume it all as one plane and go back through the GPU. Intel is planning to improve this feature over time, as we might expect.
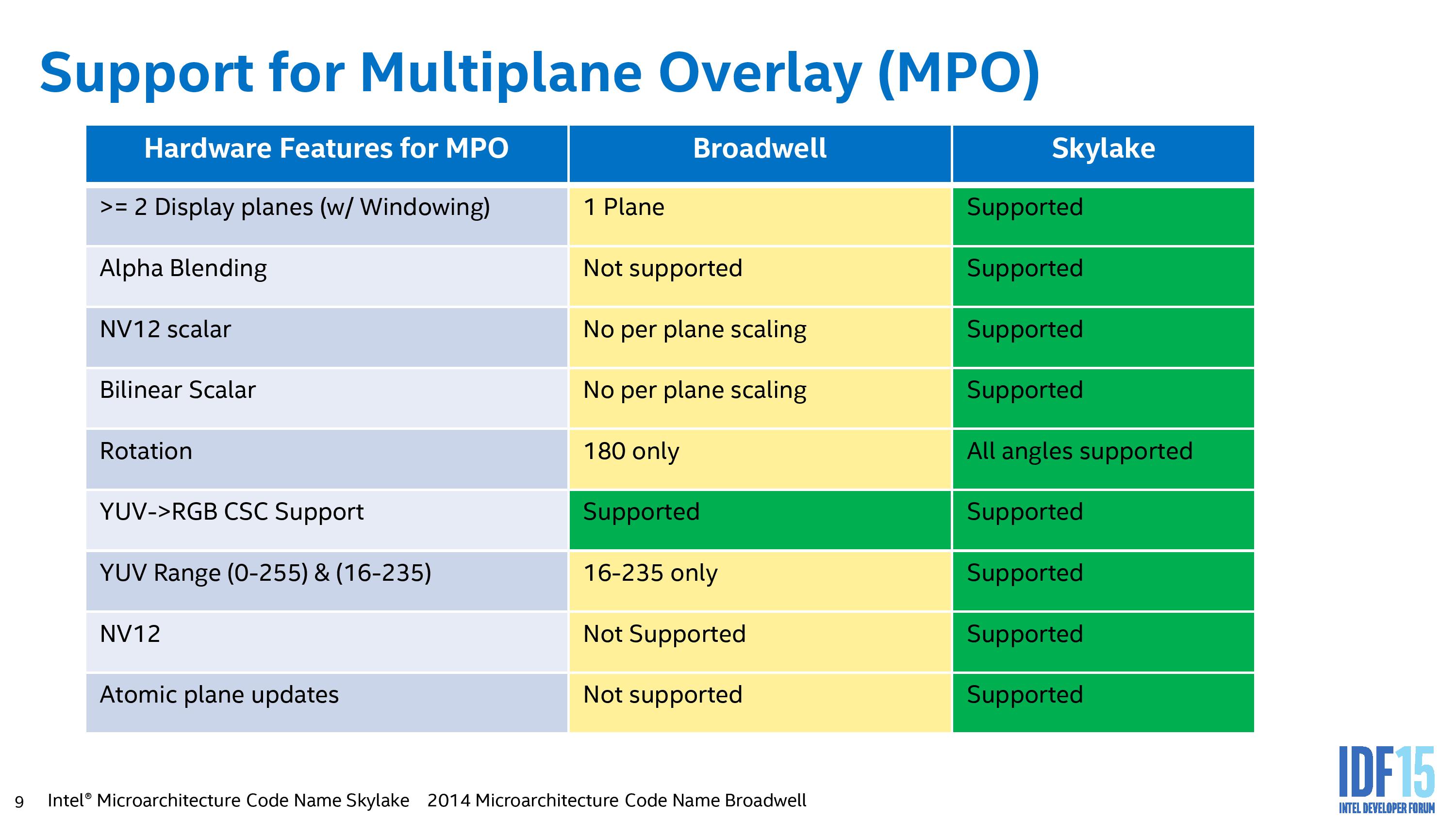
Intel’s data showed a 17% power saving increase overall while watching a 1080p24 video on a 1440p panel. Given the march to higher resolution displays and the lack of high resolution content, I can imagine this being an important player in future content consumption or multitasking.

There are a number of other media specific functions also new to Skylake, especially evolving around RAW processing in the fixed function units of the video quality engines to save power, other memory compression techniques and the encode/decode of specific formats such as HEVC and VP9. For this information, I suggest heading over to read Ganesh’s piece on Intel's Skylake GPU - Analyzing the Media Capabilities.
Power Management
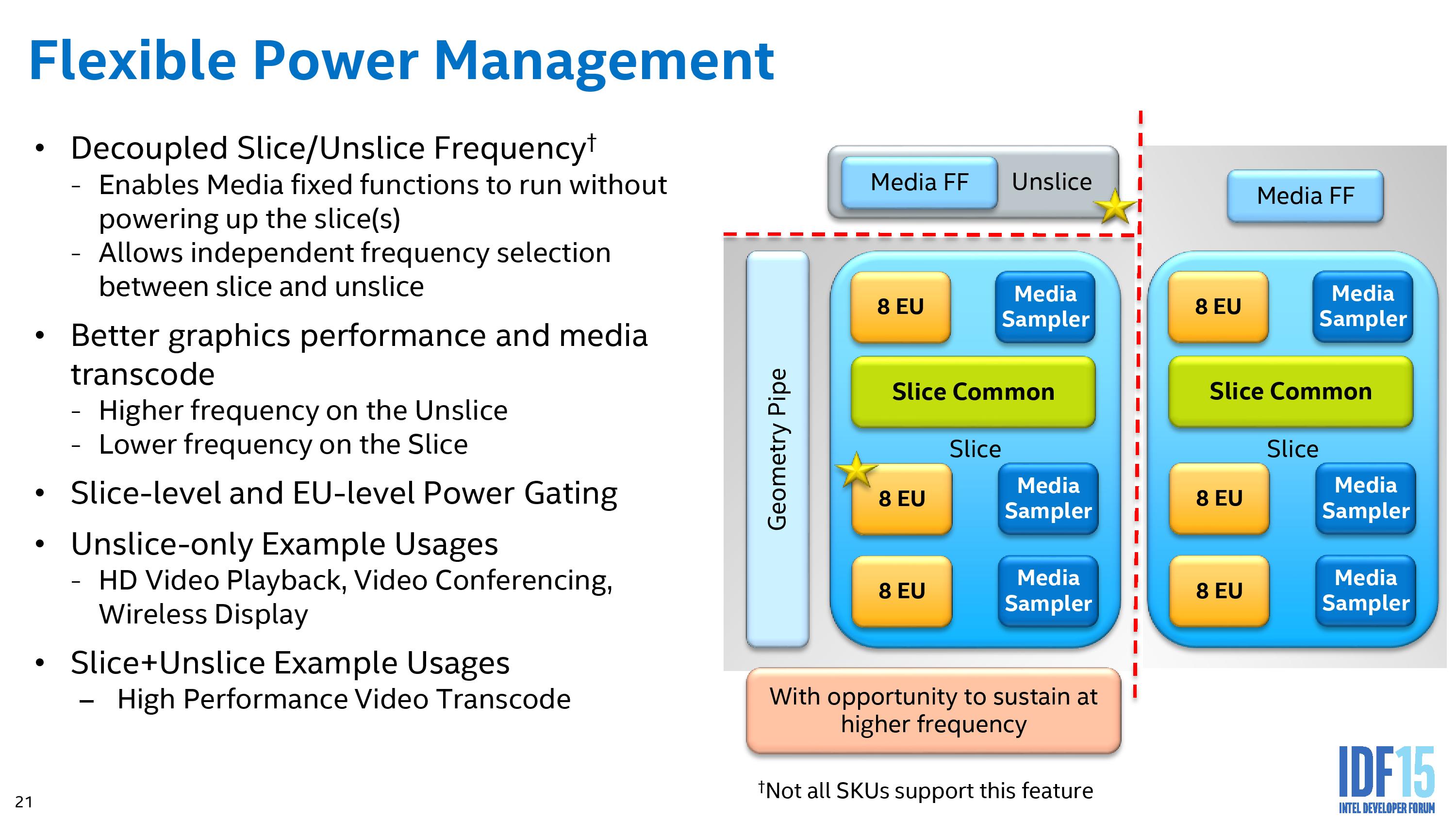
In parts of this article we’ve mentioned the effect on power consumption as part of Intel’s strategy on Skylake. This new architecture is aimed at being mobile first, but able to encompass a wide range of power envelopes from 4.5W on Core M (Skylake-Y) to 91W on Skylake-K, as well as being the basis for future Xeon processors (which currently sit at 140W under Haswell-EP). A common theme through Intel’s Developer Forum is the level of control and power gating that has been incorporated into the processor, allowing the hardware to either disable completely, move into the most efficient power mode, or even duty cycle to reduce power. A big part of this is under the term ‘Intel Speed Shift’, Intel’s new methodology of allowing quick frequency changes and responding to power loads. But first, the management is done through the package control unit.
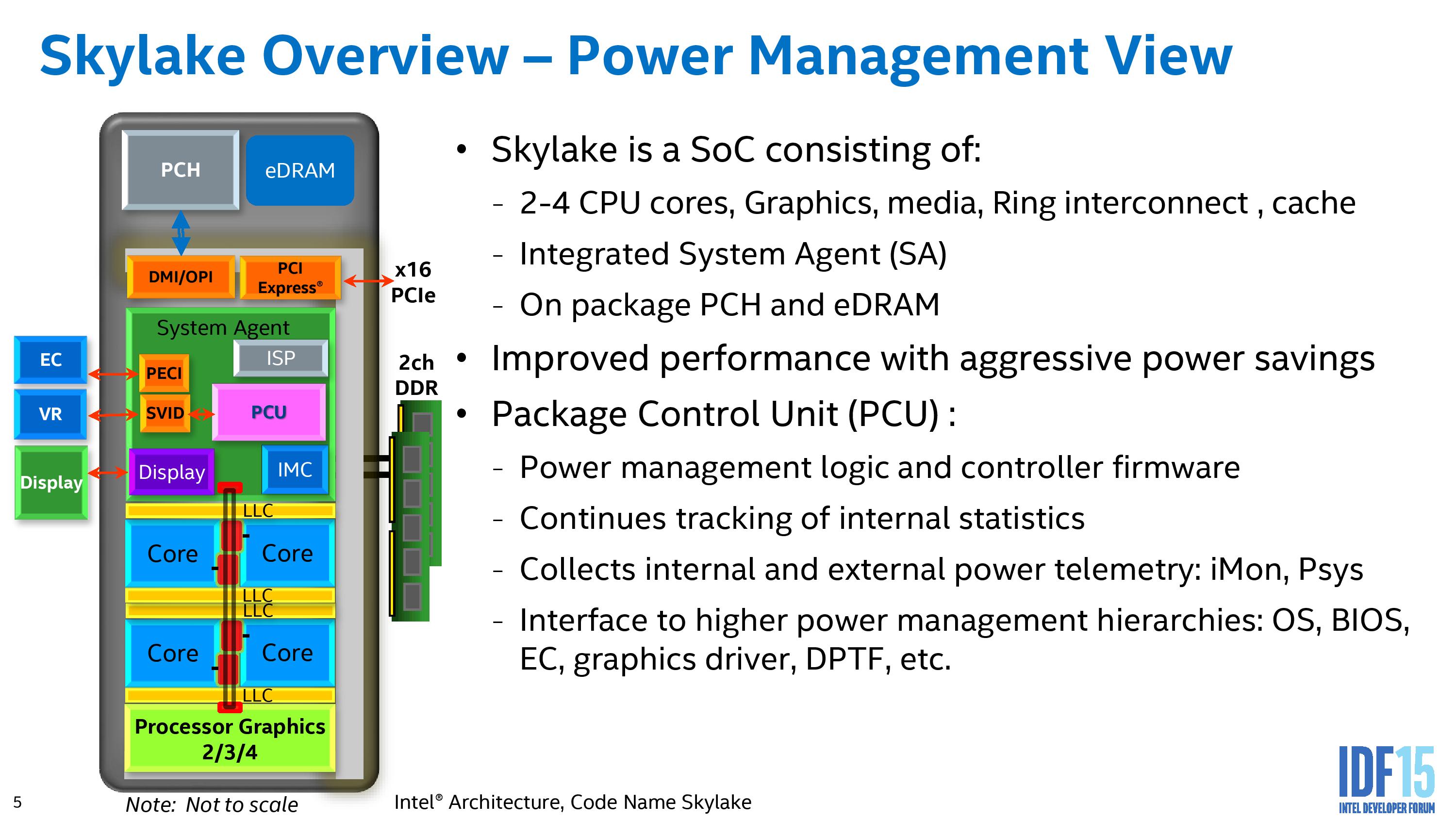
The PCU is essentially a microcontroller (we’ve seen references to a full Intel architecture (IA) core in there) that monitors and computes the power requests and consumption portfolio of the separate silicon areas, providing information that can allow parts of the CPU to be power gated, duty cycled, or adjust in frequency and voltage. We’ve mentioned in our initial Skylake review that going into the CPU itself are four power rails (more with eDRAM). This is an adjustment over Haswell/Broadwell which only had one power rail due to the integrated voltage regulator, which is now moved back on to the motherboard for a combination of reasons related to complexity, efficiency, die area and heat generation.

In all there are at least 12 power gates in a 4+2 design, extending for larger integrated graphics and eDRAM as well. Within this there are several frequency domains – one for core, one for uncore, two for integrated graphics (unslice/slice) and one for eDRAM at a minimum. Being able to react due to power demand and efficiency requirements is a key aspect of Skylake here.
Intel Speed Shift
The new way of managing this comes under the Speed Shift mantra. Intel is promoting this as a faster response vehicle to frequency requests and race to sleep by migrating the control from the operating system back down to the hardware. Based on the presentations, current implementation on P-states can take up to 30 milliseconds to adjust, whereas if they are managed by the processor, it can be reduced to ~1 millisecond. Intel likened this to a car taking a sharp bend, suggesting that a car that can adjust its speed to a greater level of control will take the bend quicker overall. The other factor of Speed Shift is the removal of P-states altogether, which is a different power paradigm to consider.

The current implementation provides a P1 frequency (‘on-the-box’) with turbo modes up to P0 and down to Pn where the processor idles at its most efficient implementation. Below this we have thermal management states (T-states) to deal with inappropriate environments to ensure hardware longevity as well as sleep states and low power modes. The P-state table is hardware defined, and the OS flips the switch between them as needed, although the level of granularity is ultimately very course.

For Speed Shift, the concept moves down to hardware P-states which stretches the range from the lowest frequency on the processor (typically 100 MHz) all the way to the single core turbo frequency (the ‘on-the-box’ turbo) and a finer level of granularity in-between which also allows for quicker changes when necessary to respond to interactions with the system to keep responsiveness high but power consumption low. This makes a lot of sense when we discuss Core M, where the difference between the base and turbo frequency can be as much as 2 GHz in some circumstances.
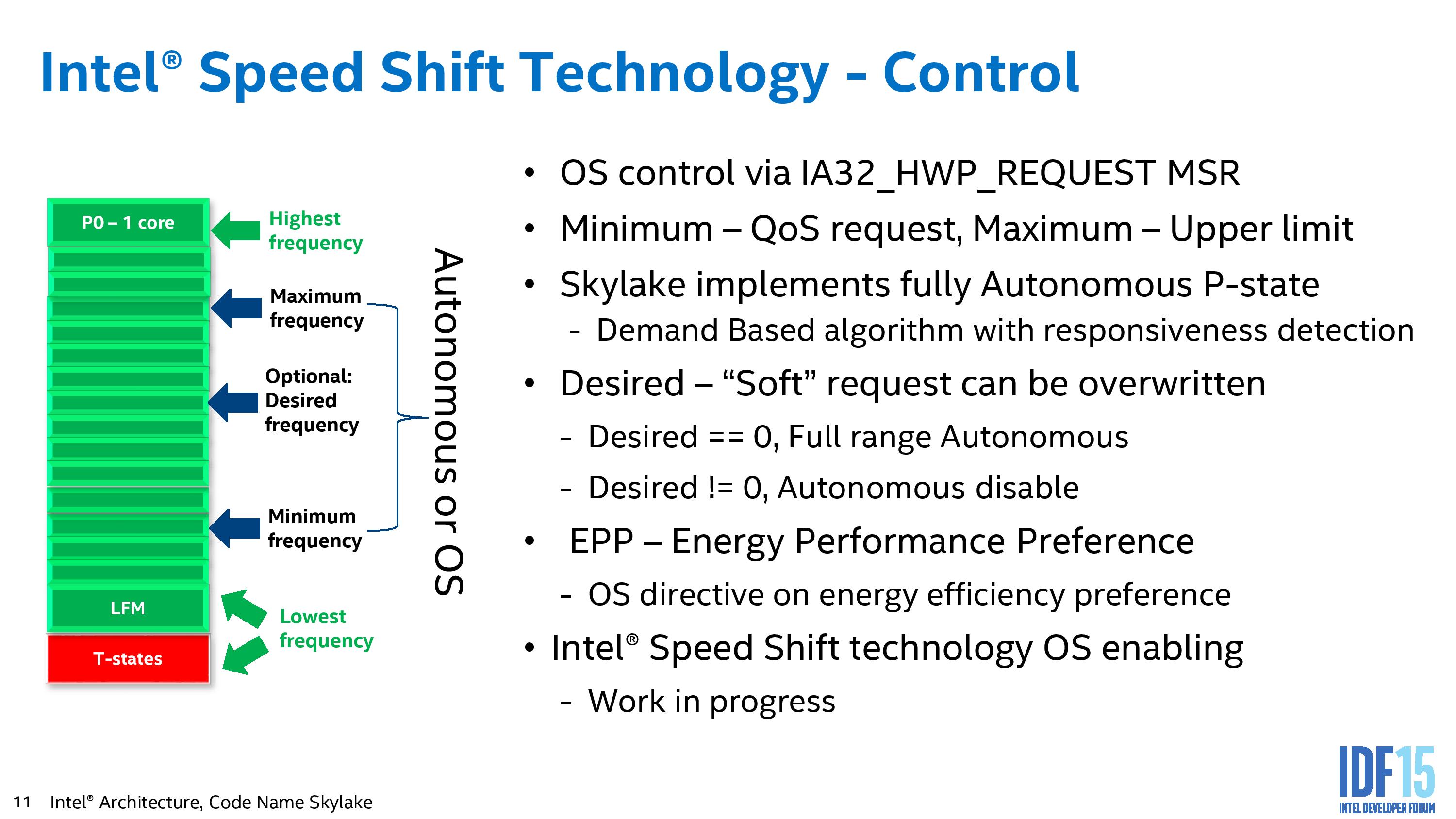
What Speed Shift entails is that ultimately the OS has the highest level of control unless thermal states kick in. The OS can define either the whole of the frequency range (from LFM to P0) or a certain part of that range and hand control back to the processor. This then becomes an ‘autonomous P-state’, allowing the adjustment of frequency to respond on a millisecond timescale. At any time the OS can demand control of the states back from the hardware if specific performance is needed. An overriding factor in all this is that the OS needs to be Speed Shift aware, and currently no operating system is. As you might imagine, Intel is working hard with Microsoft on this to begin with, and it will be part of Windows 10, as there are certain issues in Windows 8.1 and below that do not expose much of the Speed Shift control.
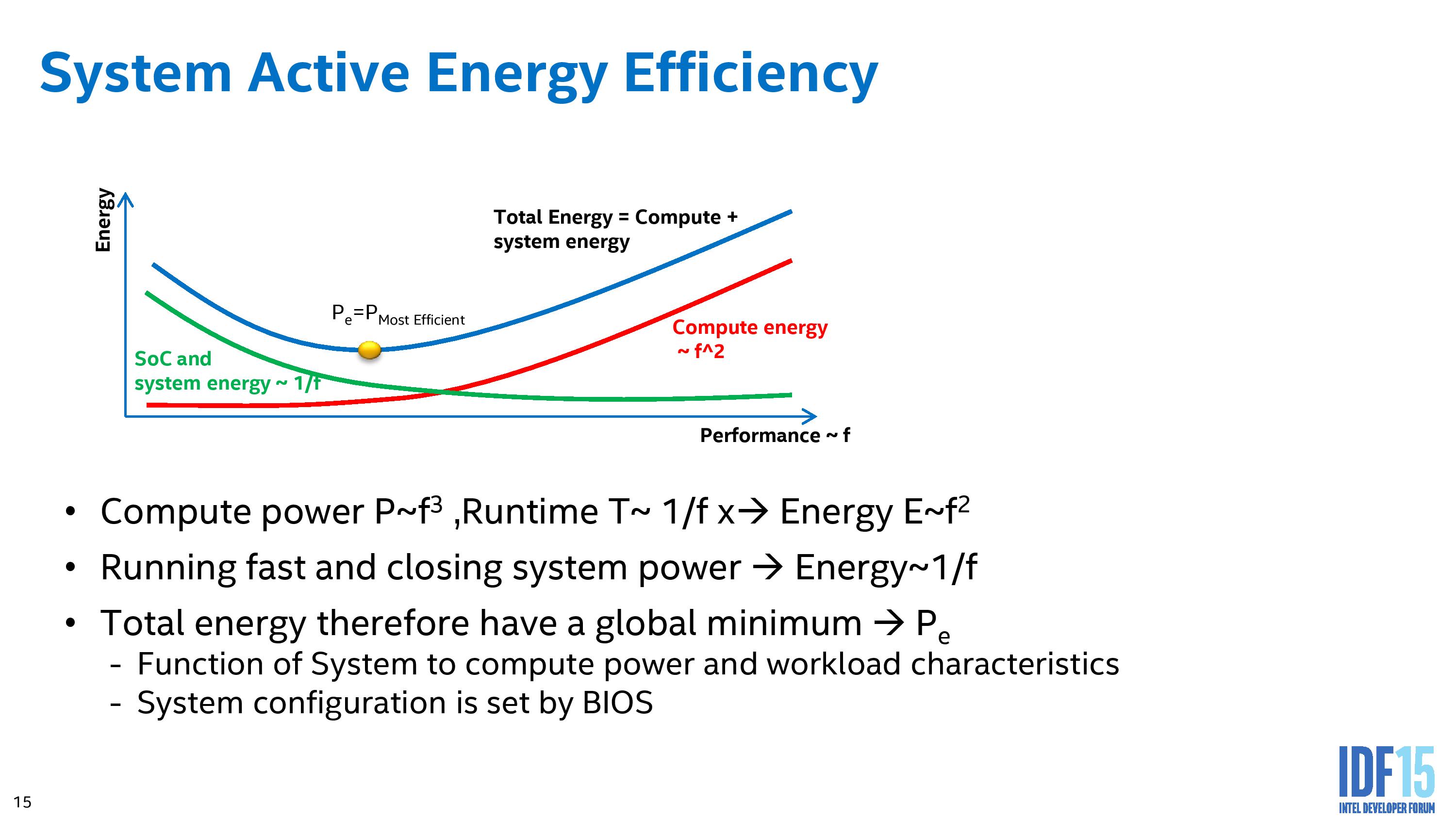
So what the autonomous processor level control will do is come up with the graph above, finding the power state that uses the least total system system power that has been exposed from the operating system. The energy used by the system will have a global minimum for efficiency, and the system will sit here as often as possible. Moving to a lower performance state in this representation actually increases the energy consumption, while moving up the performance curve has the obvious knock on effect on energy use.
It is worth noting at this point that the processor having access to the ‘total’ system power to compute the best position is a new feature of Skylake, called Power of System or Psys.

This allows the PCU in the processor to actually profile the performance and power consumption. How the algorithm reacts in this new setting comes within the segment of two Intel derived autonomous algorithms – one for low range and one for high range.
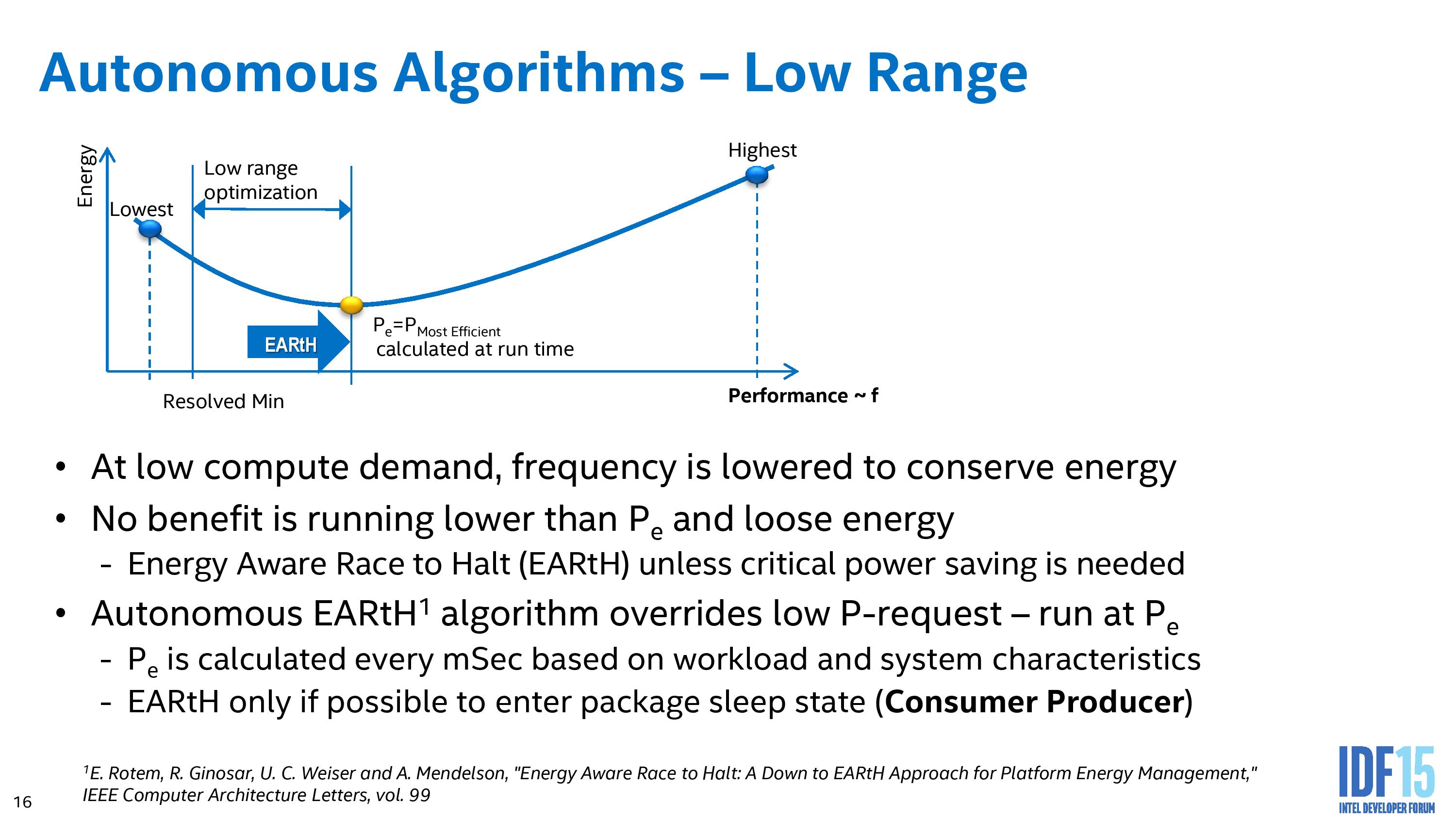

The high range algorithm is of most interest – clearly moving to higher performance affords better response times and quicker time-to-completion, albeit at the expense of energy efficiency. It can be difficult to ascertain whether a user wants something done quickly, or something done efficiency (say, image filters while running on a deadline for a work project compared to image filters casually looking through home photographs). The underlying autonomous algorithm can be preprogrammed (by the OEM or the OS) to respond based on a percentage performance increase for percentage loss in efficiency. This means that some situations might be 1% performance for 2% efficiency, whereas others might go further up the curve to 1%/10% in order to squeeze that extra bit out. Intel’s algorithm also performs an analysis of the workload, whether it is sustained, variable, bursty or can be moved to fixed function hardware, but at any time the OS can jump in and either adjust the algorithm characteristics or take control altogether.
The end goal of Speed Shift is not to increase performance. Running Cinebench at a steady state performance profile will get zero benefit. Intel is aiming specifically at rapidly changing frequency scenarios here, such as office work, moving through PDF documents when images are loading, or conference calls requiring variable load encoding due to data from the camera. Intel stated that web apps, similar to those used in many businesses, are the best test to show benefit, and during IDF Intel warned us (the media) that standard benchmark profiles that speed through user entry significantly faster than a normal user would not see any benefit from Speed Shift.
Update 9/3: We have received word from Intel that Speed Shift will be enabled on all Skylake systems with an up-to-date Windows 10 platform.
Power Control Balancing
At this point, Speed Shift is primarily geared towards the processor cores although there is some level of P-state control in the integrated graphics as well. Under a sustained workload, the power available to the system has to be split to where it is needed, and as we saw in our overclocking of Skylake-K, when you increase the wrong one (CPU) while doing a workload that is dependent on other things (GPU), it can lead to a negative performance difference. By virtue of having access to the total system power, this allows Intel to adjust how it manages that power balance.

For device OEMs looking at the Skylake-YUH processors, they can define the following characteristics in their system – rolling average temperature limit (RATL), SOC/enclosure temperature (PL1), regulator sustained current (PL2) and battery current protection (PL3). This allows the system to pull up to PL3 from idle very briefly, before being limited to a current drain of PL2 for a short duration then migrating down to PL1 when the system temperature limit is reached as determined by the RATL. This gives the OEM a good fine control on the limits of the system, but distribution of this power comes to the workload aware balancer.

The controller monitors the workload in question based on data transfer and compute, and then can split the power states as required between the cores, graphics and system in order to keep the sum power within the PL1 limit. As shown in the diagram above, the balancer can only give to one when it takes from another, and where possible it will consider which elements of the system might provide better efficiency while keeping performance as expected.
Duty Cycling
Throughout all of the power optimizations mentioned so far – and indeed many of the power optimizations at the heart of the Core architecture over many generations – has been the concept of race to idle or race to sleep. The idea is simple enough: get the job done as soon as you can and then get the CPU back to an idle state. This is an effective strategy because processors operate on a voltage/frequency curve, resulting in higher power consumption at higher frequencies, and conversely power consumption quickly drops at lower frequencies.
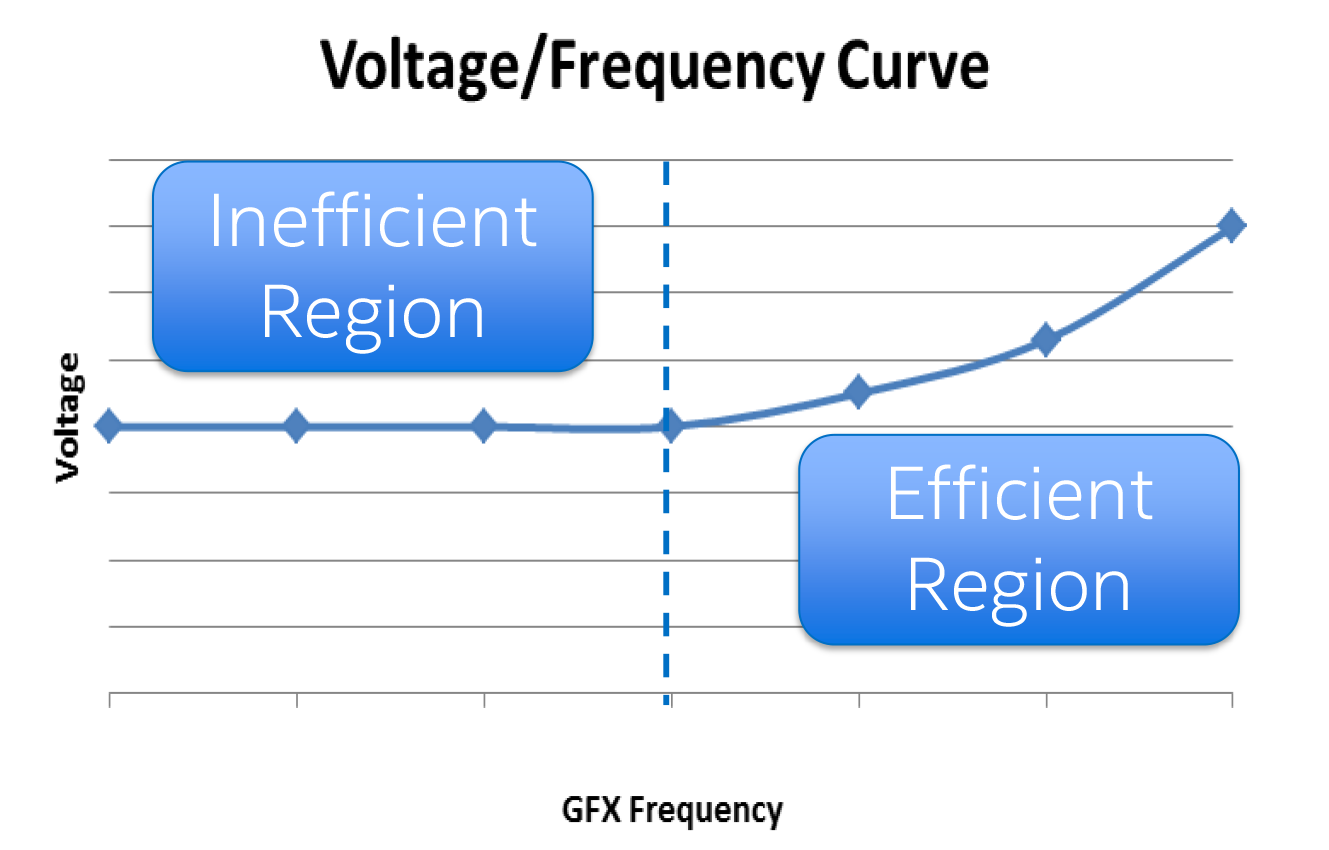
However as Intel seeks to further optimize their power consumption, they have been running headlong into the laws of physics. The voltage/frequency curve is just that, a curve, meaning that it flattens out towards the bottom. As it turns out it flattens out more rapidly than you’d think due to the existence of a threshold voltage for transistors, which is the minimum voltage required for a transistor to operate. As a result of this effect, idling at even lower frequencies sees rapidly diminishing returns once you drop below the threshold voltage, and at this point reducing frequencies is no longer an effective way to reduce power consumption.
In Broadwell, Intel introduced the idea of Duty Cycle Control (DCC) to solve the idle power savings problem for the processor’s iGPU. A solution that is both a bit brute force and a bit genius, with DCC Intel outright shut off the iGPU for a period of time, rapidly cycling between the on and off states, the process of duty cycling. With DCC Intel was able to save power in a very straightforward manner, bypassing the idle power problem entirely and just not running the iGPU when it wasn’t needed. While there is a small amount of overhead to waking the iGPU up and putting it back to sleep, the relative power savings from DCC were close to the overall amount of time the iGPU was turned off.

Catching up to Skylake then, Intel has taken the duty cycle concept to the next stage and implemented DCC on the CPU cores as well. Similar to Broadwell’s iGPU implementation, this involves rapidly turning the CPU cores off and on to achieve further power savings beyond what idling alone can offer. In the case of Skylake this process can occur as often as every 800 microseconds, with Intel picking a point that balances the cost of transitioning with the need to avoid having the CPU stay off for longer than the OS can handle. In the slide above, the duty cycle rate is set at 50%, with equal time between Pe and C6, although this can be adjusted as needed.
Of all of the power saving features introduced in Skylake, duty cycling the CPU cores is likely to be among the most potent of these features. Duty cycling allows Intel to reap many of the power benefits of C6 sleeping without the cost of fully going to sleep from an OS perspective, and it allows Intel to cover edge cases where a workload is present that requires the CPU cores to remain awake without doing much in the way of actual work. Put another way, duty cycling on Skylake allows Intel to fully maximize the amount of time the CPU cores and the iGPU are kept in low-power sleep states.
Back to the L2 Cache
In order to make the power section more complete, we want to cycle back to our L2 cache power saving scenario. Several pages ago in the CPU architecture page, we mentioned that there are changes to the L2 cache that have a knock on effect on power. What Intel has done in Skylake is reduce the L2 cache associativity (the way it tracks cache data) from an 8-way design to a 4-way design. This has two effects – power savings but performance penalties. Since at least Sandy Bridge (and even before), Intel has always stayed with an 8-way L2 design per core on its main performance architectures, so moving to 4-way was a little surprising. Speaking to Intel, the power savings are significant enough to do this, and they have put measures in place such that the L2 cache miss latency and bandwidth are both significantly improved in order to hide the performance difference this change it might create. We are also told that this change allows their corporate and enterprise platforms an extra element of adjustment, and we should keep an eye on these when the E5 processors are released (which by our estimates is at least 2017?).
Other Enhancements
Aside from Speed Shift, the L2 cache, and our previous notes regarding fixed function hardware in the graphics, Intel has a few other power considerations.
With power in mind, Intel also pressed home during IDF about a general efficiency improvement across the board, extending to the ring in the core, a digital PLL, serial power IO and advanced power management. As mentioned before, Intel has moved the integrated voltage regulator (FIVR) that we saw in Haswell and Broadwell back out of the processor, leaving it in the domain of the motherboard. There was no clear cut answer to this, but it is known that FIVRs are not always very efficient at low loads and can cause high die temperatures when under stress. By moving it to the motherboard, it becomes an external issue. There is the potential for Intel to use linear regulators at low power, although as we understand these do not scale in ways that Intel can find them to be beneficial to the design process. We are getting big hints that we will most likely see the FIVR move back on to the design, although it is unclear if this will result in a specific design focus or if it will happen across the board.
What to Expect
With Intel going for a full YUHS launch today, looking up and down the stack there are a number of interesting things to consider at each segment. Starting with Skylake-Y, or Core M, the new branding to m7/m5/m3 will hopefully make it easier for users to ascertain the performance of their processor, but it also allows Intel to inject vPro into various SKUs, such as the upcoming update to Intel’s Compute Stick.

In the mini-PC space, through various sources in the industry, we are told that it is the vPro moniker for these devices (such as the NUC and Compute Stick) that generate the higher proportion of sales. At this point, the vPro versions of Core M are not due out until later in Q4/even Q1, but I assume we should see something at the Consumer Electronics Show during the first week of January.
One element we haven’t touched upon is how Intel will implement different TDP aspects to both its Skylake-Y and Skylake-U lines. With Haswell and Broadwell, most processors had a cTDP Up and a cTDP Down mode that allowed the device OEM to take a processor and move it slightly outside its normal TDP window, perhaps to take advantage of a chassis design they already had and either increase battery life or increase performance.
Now due to Speed Shift, one could argue that cTDP down is less relevant, and when cTDP up is available and a Speed Shift aware operating system is installed, that setting might be used as well. Because Speed Shift is not universal, there is still this element of cTDP Up and Down to contend with. To insert a few more caveats, it seems like SDP (scenario design power) might also be part of the equation, especially in the Skylake-Y domain.
It is worth noting that the Skylake-Y package is crazy small. At IDF Intel showed off a finished Skylake-Y package to demonstrate the CPU die size in relation to the package size, and to compare the overall package size to the already small Broadwell-Y package. While both packages are still 16.5mm wide, Intel has compacted the overall layout and squared off the CPU die, bringing the height of the Skylake-Y package down from 30mm to 20mm, a 33% savings in package size.

Meanwhile Intel also had the other BGA Skylake processor packages on display as well:

Actually in this shot, we can calculate the die size of the Y 2+2 die to be approximately 98.5 mm2 (9.57mm x 10.3mm). This is compared to the 4+2 arrangement on Skylake-K which we measured at 122.4mm2. At this package size of 20 x 16.5 mm, Intel is claiming a 40% gain in graphics performance for Skylake-Y over Broadwell-Y, which will be interesting to compare when we get some samples in house.
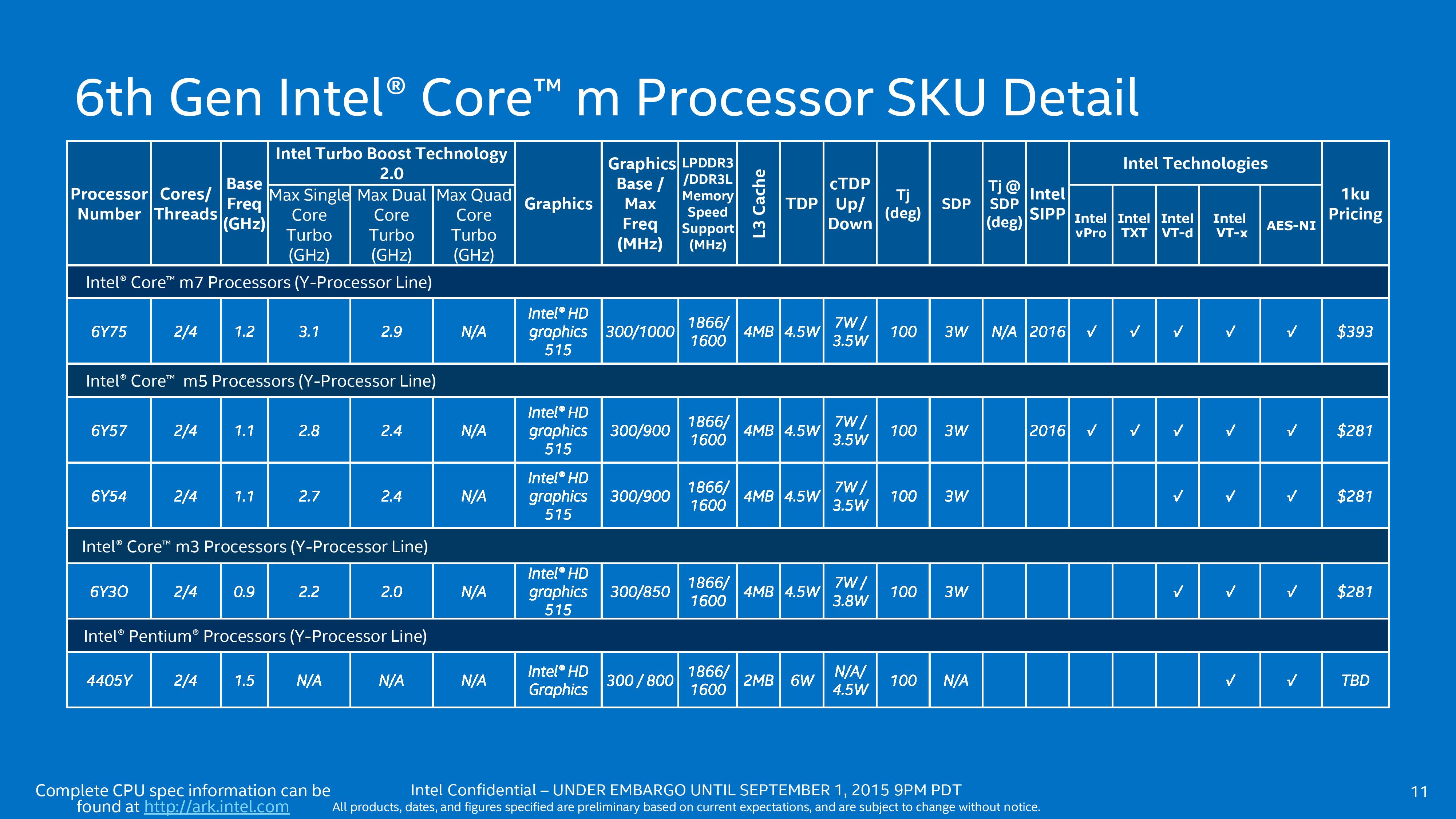
Skylake-Y still comes in as Intel’s premium low power processor, with 1K pricing from $281 to $393. That more or less aligns with Broadwell-Y, but we also get a Pentium model that is severely cut with no turbo mode and only 1 MB of L3 cache per core.
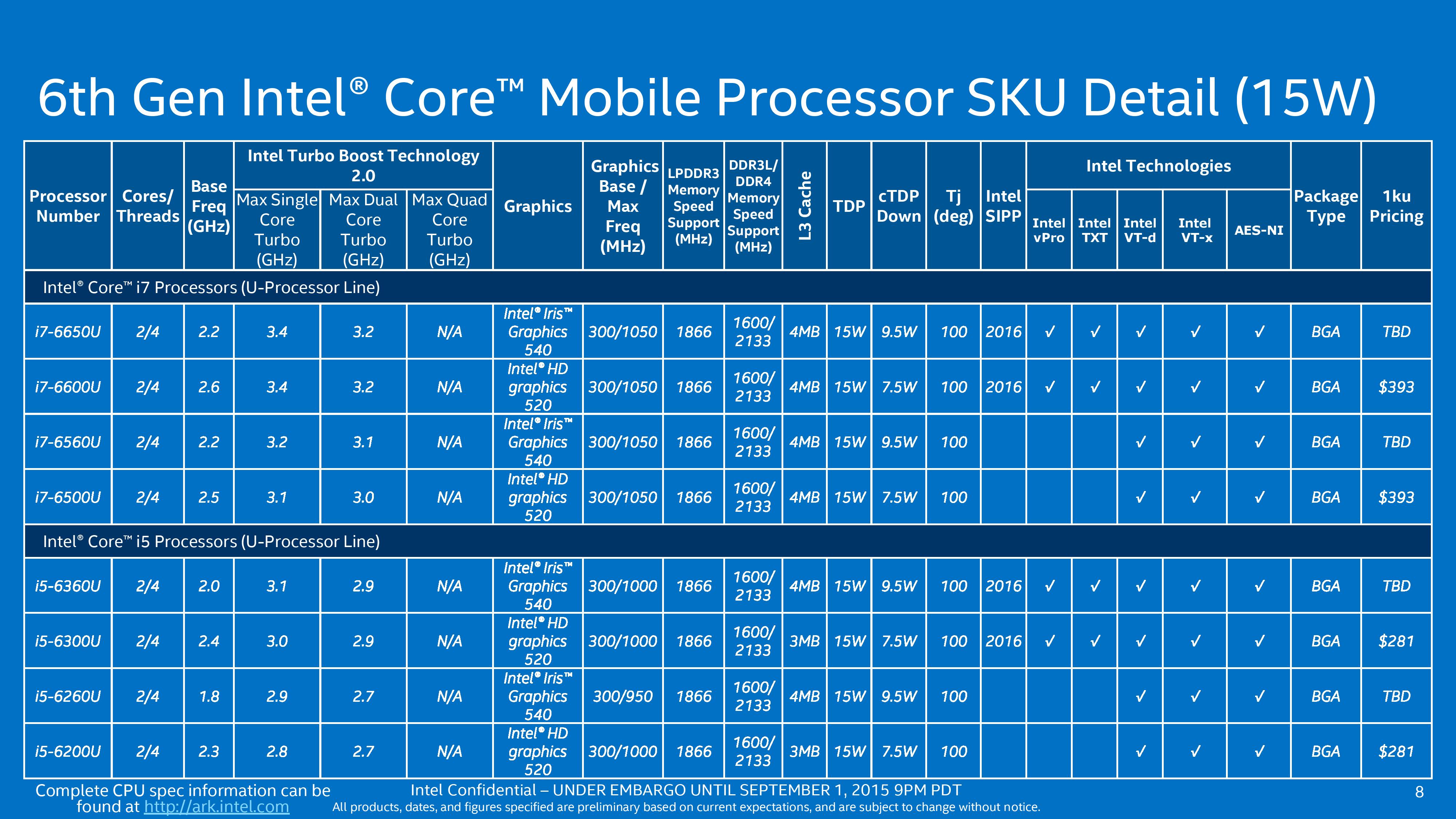
The 15W models of Skylake-U either follow the 00U naming for GT2 graphics (24 EUs) or 50U/60U for GT3e graphics (48 EUs with 64MB eDRAM). The pricing on the GT3e parts is not given as they will be coming later in the year, but it can be pointed out that the base frequency for the GT2 parts is actually higher than the GT3 parts. Also, the L3 cache on the i5-U processors with GT2 is at 1.5 MB/core rather than 2 MB/core. Normally all the i5 parts would be below the i7 parts, but because the eDRAM arrangement moves up to 2 MB/core, the i5-U parts with GT3e have to comply.
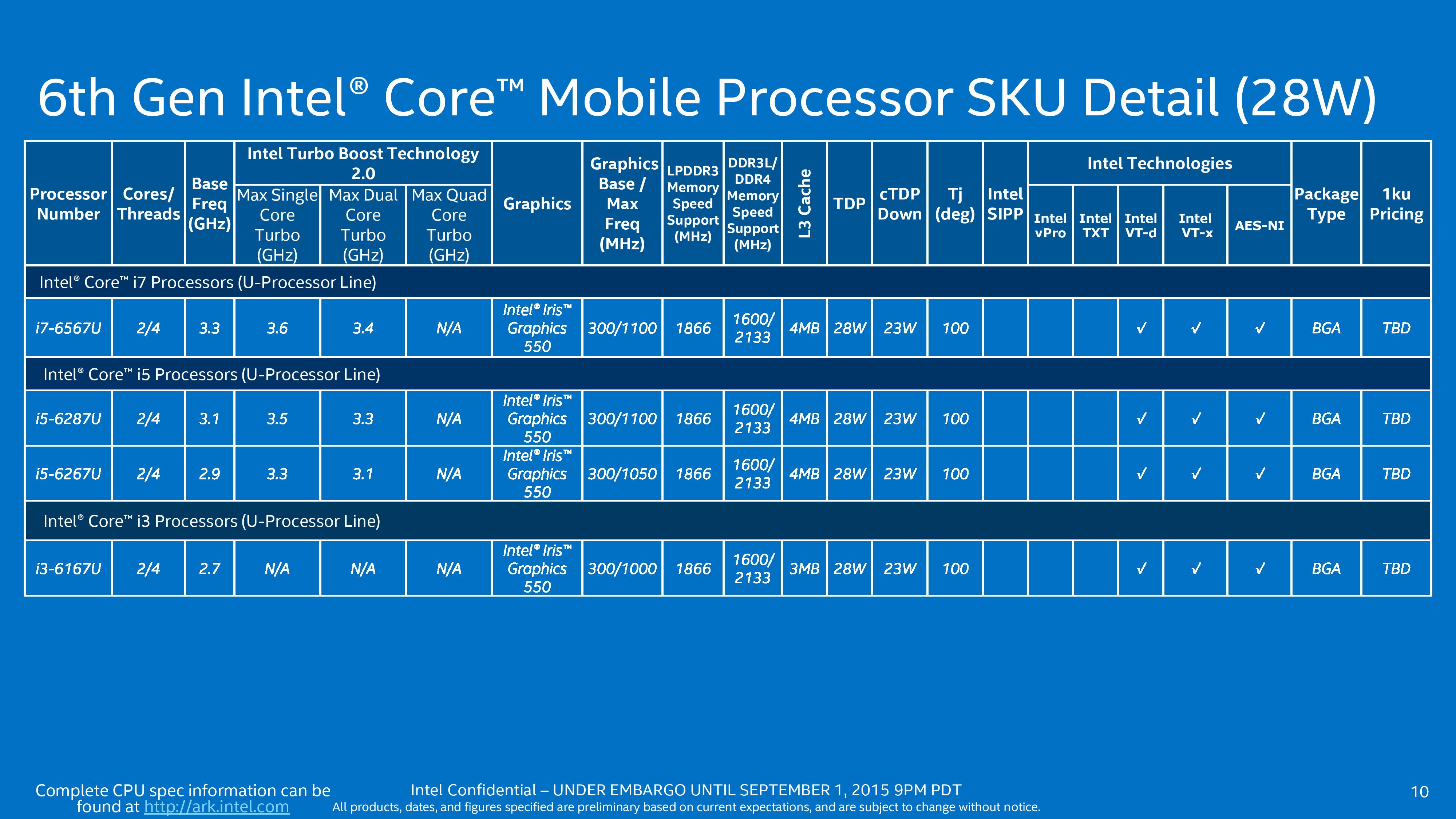
Moving up to 28W with Skylake-U presents us with the higher power GT3e models. Similarly, the pricing has not been announced for these but for all the processors the base frequency is relatively high (2.7 GHz to 3.3 GHz) with only a small jump to the maximum frequency. The i3 at the bottom without any turbo frequency but with GT3e would be an interesting part to play with.
At 45W, the Skylake-H mobile processors almost all move into quad core territory here, aligning with the power increase, but also moving down to GT2 arrangements. We get a vew vPro enabled parts here too, and the pricing of the i5 seems quite reasonable.
There is one part that stands out – the i7-6820HK. This is Intel’s mobile part that can be user overclocked. Yes, that’s not a typo. This processor is designed to go into laptop systems that have sufficient cooling (either high powered air… or water) and can be pushed when they are needed. Expect to see this part in the large 17” desktop replacement gaming systems over the next few months.
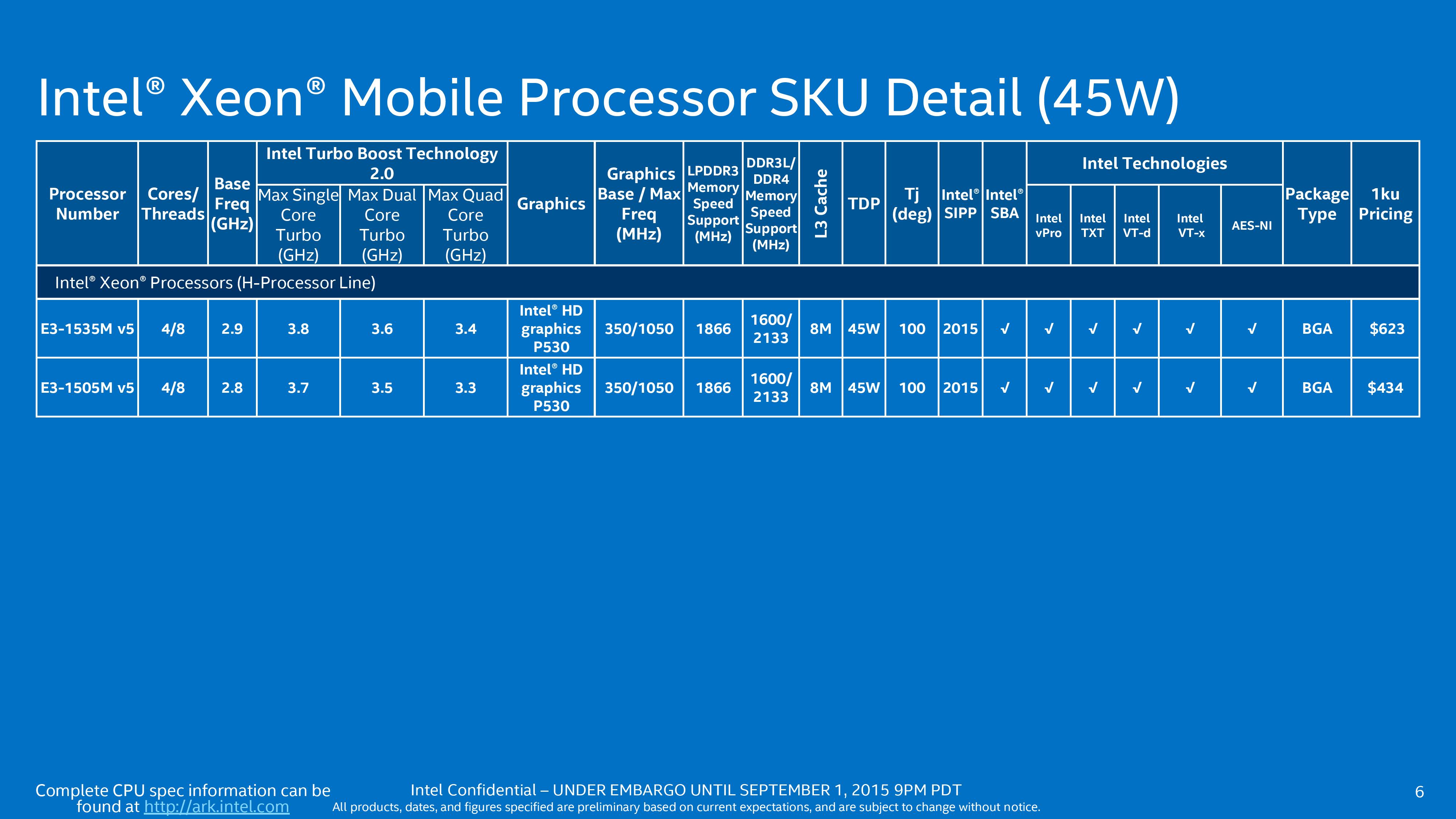
Intel is also releasing a couple of mobile processors under the Xeon branding. This means ECC support and all the other Xeon benefits, but in a processor specifically designed for notebooks rather than a repurposed desktop processor that might not fit properly / give the best ergonomics. When these were announced, it was perhaps wishful thinking that Xeon would come down to 15W, perhaps offering ultrabooks with this feature set, though I imagine at 45W we will see some desktop-replacement workstations with professional grade graphics cards, such as the already-announced Lenovo workstation laptops.
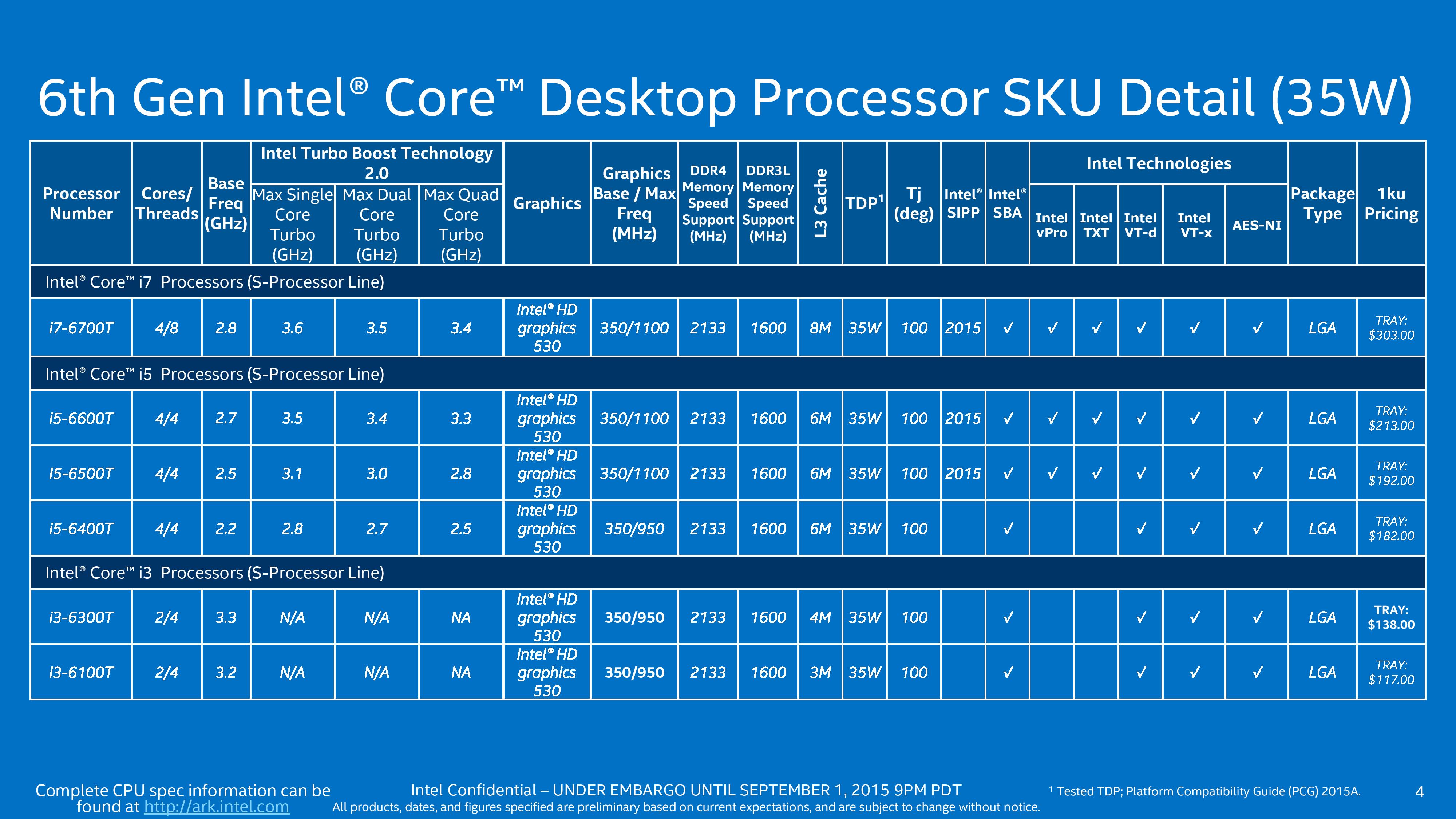
On the Skylake-S side of the equation, the processors come in two segments. Here is the list of the low powered processors that have the ‘T’ in the name, or unofficially known as ‘Skylake-T’. These are all 35W, some with vPro, but covering the i3/i5/i7 lines sufficiently.

The non-T and non-K desktop processors come in at 65W, and there are no real surprises here in the product lines as they migrate well enough from previous generation designations. All the Skylake-S i3/i5/i7 processors have HD 530 graphics.
Beyond Skylake and to Kaby Lake
Post Skylake, Intel is breaking from the tick-model to tick-tock-tock, posting a third generation on 14nm called Kaby Lake (pronounced Kah-bee, as far as we were told).
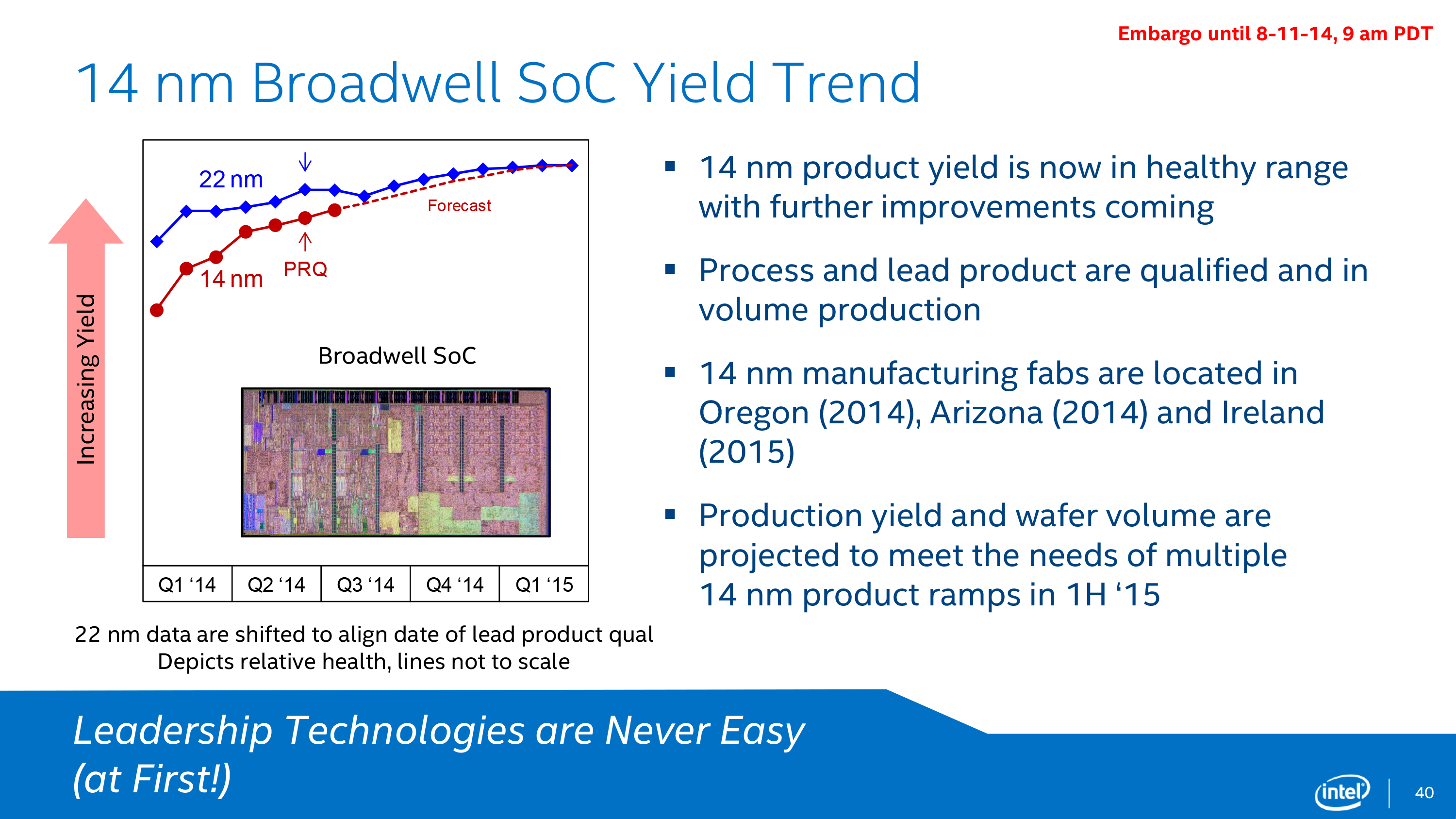
This stems from the issues of moving to smaller process nodes. At 14nm, this equates to only 90 silicon atoms, meaning ever more intensive manufacturing is required which drives up cost and reduces yield. Due to the issues Intel had at 14nm using their second generation FinFET method and more advanced double patterning, initial costs were high and yields were lower than expected for the timeframe, pushing Broadwell to a later-than-expected timeline. Skylake was kept to the regular timeline, resulting in a brief outing for Broadwell (on the desktop especially). But we suspect that similar reasoning is behind a delay from 14nm to 10nm –more esoteric ways under conventional methodology are required to keep driving the node down, and with that comes extra challenges that delay both time to market and yield numbers before tweaking the design.
We’ve mentioned in the past that the development of extreme-ultra-violet (EUV) technology is one element that could assist this drive down, however Intel is not expected to implement this for 10nm but rather for 7nm, which is still several years down the road. To that end, tick-tock is not dead, but merely stretching out.
Final Words
Based on our testing of Skylake-K, performance per clock did not impress as expected, but by going back several generations it gave an overall performance boost worthy of an upgrade from 3-to-5 year old platforms where more CPU performance might be a good thing to have. The chipset side of the equation is also blown wide open, with PCIe ports being able to provide any PCIe x4 or under idea through the chipset without having to share bandwidth.
The reasons for Skylake-K’s clock-for-clock performance relates to the fact that Skylake is a mobile first design, and Intel has focused a lot of resources in two areas. First is power delivery, by adding more power gating and finer frequency control direct to the hardware through Speed Shift, the processor can take advantage of unused parts as well as improving the power consumption of a non-steady state workload. Speed Shift does two things - it requires operating system support, but it allows the operating system to hand control of frequency adjustments back to the hardware within an OS specified range. As the processor is able to adjust its own frequency settings almost 30x faster than the operating system, it can respond to dynamic workloads such as those experienced in day-to-day use of a device faster than the OS. The second part of Speed Shift relates to the power states of a system, and the Skylake platform allows this hardware control to be substantially more granular than the high level P-states, allowing the onboard controller to determine the best efficiency mode to run the processor with respect to system power (which is also now tracked). When the system is in its most efficient state and performance is not a concern, Skylake can also induce a duty cycle for the processor cores, switching them on and off, to remain at the most efficient power state when performance is not a priority.
Also on the power side of things, the integrated graphics gets a boost here too. Intel has added a number of fixed function units, such as those for HEVC decode, to reduce power as well as more power gating and frequency domain differentiation. Generation 9 graphics also gets added RAW processing functionality for camera setups, and Multi Plane Overlay performs stretch/rotation and translation of parts of the desktop directly on the display controller rather than requiring trips out to main memory to waste power in doing so. Multi Plane Overlay is still in its infancy, but it is part of the graphics platform that Intel seems keen to improve over the years. All together, from a power perspective, it will be interesting to feel the claimed benefits of the new architecture.
The other avenue for Skylake’s design choices stems from the corporate or business aspect of Intel’s platform. At some point a form of the Skylake architecture will find its way into an extreme platform Xeon, which means the design must be able to cope from 4.5W in Skylake-Y up to a potential of 140W in a Xeon E5 (which is what currently exists on Haswell-EP). The best way to do this is by making the design more modular, adding in performance when necessary. While Intel has not been explicit about which segments are more modular than others, we have been indicated that the L2 cache and the movement from an 8-way associative design to a 4-way design is part of this. It is worth noting that this change also affords power benefits for Skylake, at a small expense in performance.
Also, as per our architecture analysis, despite the decrease in L2 associativity, CPU performance limited environments benefit from wider and deeper execution buffers, attempting to extract as much instruction parallelism as possible. Skylake extends this by providing a larger out-of-order window for micro-ops to queue into, providing larger buffers for in-flight data (both load and store), doubling of the L2 cache miss bandwidth, general improvements to the branch predicition to reduce unnecessary speculation, an increase in micro-op dispatch and retirement as well as new instructions for better cache management. As per our understanding, these under-the-hood changes will be seen as the Skylake platform develops.
From the processor perspective, Skylake affords an interesting dynamic. For the most part, the TDP ratings in the stack of processors remain similar to those in Broadwell, meaning that the 15W design for Broadwell should only need minor adjustments (new motherboard, new ports for new features) and still provide sufficient cooling but at better performance and/or more battery life. Despite not being directly released today, Intel is talking a lot about its eDRAM implementations, both as 4+3e (quad core, GT3 with 64MB) models and 4+4e (quad core, GT4 with 128MB) models.
The addition of Iris and Iris Pro graphics to Intel's 15W and 28W SKUs stands to significantly improve the state of graphics performance on ultrabooks and near-ultrabook form factors. Intel has offered processors with more powerful graphics since Haswell, although seemingly begrudgingly, withholding larger GPUs and eDRAM for the 45W SKUs. While OEMs will be paying more for these higher performance processors, these new Iris and Iris Pro configurations are practically a love letter to Apple, who has long desired more powerful iGPUs for their products and was a major instigator of the Iris lineup in the first place. We wouldn’t be the least bit surprised to see Apple jump on these new parts for the 13” MacBook Pro and the MacBook Air series, as they deliver just what Apple has been looking for.
This ends up being doubly beneficial for all concerned, as the actual working nature of the eDRAM has changed, making it more like a DRAM buffer with lower latency and transparent to software, but it is clear that Intel is releasing substantially more parts than it ever did on Haswell and Broadwell, with more to follow as time progresses. It is unclear if an eDRAM part will make the desktop however, though we might imagine a Skylake-H part with eDRAM in a future iMac in order to update the line.
Two new parts that will be constantly discussed over the next few months is the overclockable mobile processor, the i7-6820HK and the mobile Xeons. Firstly the overclockable processor is most likely only going to be in the large desktop replacement type of environments, coming out as a 45W part, but it will most likely end up in gaming systems where users want to add more heat and voltage to their gaming system. We might see some interesting laptop designs as a result of this. The mobile Xeon aspect of the release is Intel's first foray into Xeons specifically targeted at mobile, rather than a repurposed desktop processor in a bulky chassis. At this point, Intel is only launching a couple of E3 v5 models at 45W, suggesting that they will still end up in large workstation chassis with professional graphics cards, but it implements a step that Intel might take down into the notebook segment with both ECC and vPro and other Xeon features that translate well into business environments.
As always, if previous analysis has proven anything, architecture discussions can promise much on paper but where it really matters is if it translates through the devices into which the architecture is used. Implementations such as Speed Shift, fixed function units and an increase in power gating/frequency control should all impact a substantial segment of users, assuming all these functions have the correct operating support. Arguably how earth shattering or paradigm shifting Intel’s Skylake platform is can be up for discussion, but this week is the tech show IFA in Berlin where we expect a number of OEMs to start showing devices as well as processors actually going on sale. We will update with product testing when we can get our hands on them.






